概要
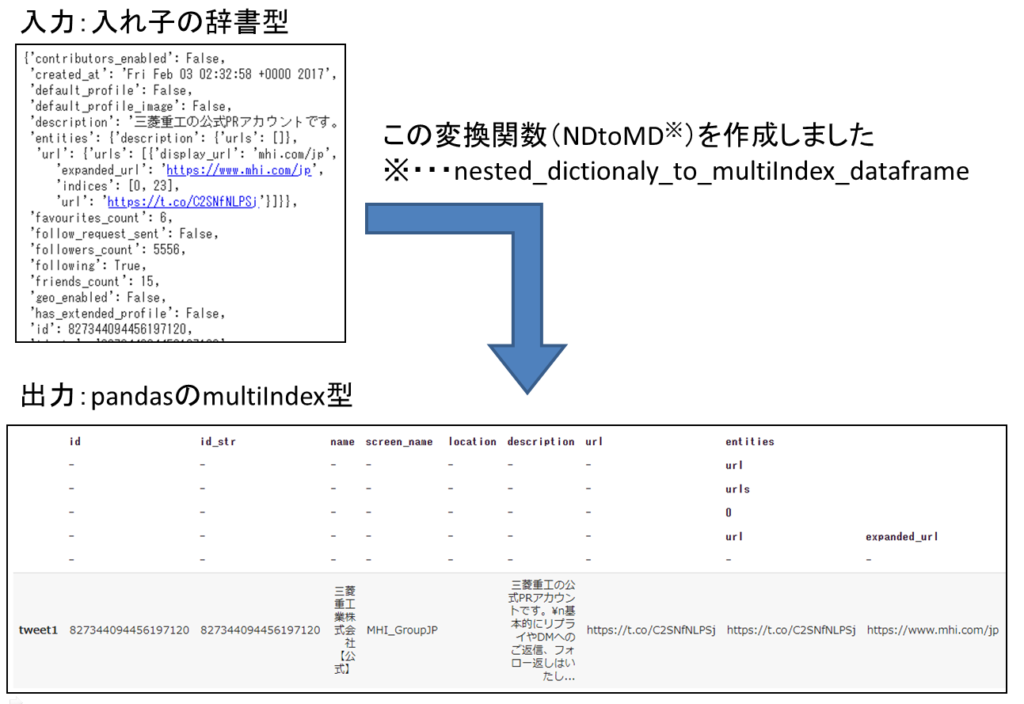
TwitterAPIで取得したツイートのデータなど、データ構造がjsonで定義されているデータを分析したいときには、pandasで入力(json→入れ子のDictionary型)をMultiIndex型で読み込んでくれる(下図参照)と使いやすいと思うのですが、調べた範囲ではそのような機能やツールは見つけられませんでした。そこで、それを実現するコードを自作したので、紹介したいと思います。
作成スクリプト
NDtoMD(Nested Dectionary to MultiIndex DataFrame)について記載します。
動作環境
本スクリプトはPandasのバージョン1.1.5で動作確認しています。
コード
def NDtoMD(inputNDict, root=True, index_name='index', depth=None):
"""
入れ子のDictionaryをPandasのMultiIndex型に変換する
Nested Dectionary to MultiIndex DataFrame
Parameters
----------
inputNDict : Dictionary
入力となる入れ子の辞書型オブジェクト。
root : bool
(オプション)内部で再帰的に使うため存在するパラメータ。Trueから変更しない。
index_name : str
(オプション)出力のindexの値に用いる。
depth : int
(オプション)出力のマルチインデックスのレベルを増やしたいときにそのレベルの値を指定する。
Returns
-------
df_items : DataFrame
マルチインデックス型をカラムに持ったデータフレーム。
"""
if type(inputNDict) == list:
dict_input = {i:inputNDict[i] for i in range(len(inputNDict))}
else:
dict_input = inputNDict
dict_items = OrderedDict()
if (root is True) & (depth is not None):
max_level = depth
else:
max_level = 0
for key in dict_input.keys():
#print(key)
value = dict_input[key]
if (type(value) == list) | (type(value) == dict):
if len(value) == 0:
df_add = pd.DataFrame(['empty'], columns=['-'])
else:
df_add = NDtoMD(value, False)
if max_level < len(df_add.columns.names):
max_level = len(df_add.columns.names)
else:
df_add = pd.DataFrame([value], columns=['-'])
dict_items[key] = df_add
for key in dict_input.keys():
df_add = dict_items[key].copy()
levelnum = len(df_add.columns.names)
if levelnum < max_level:
for i in range(max_level - levelnum):
dict_level_arange = dict()
dict_level_arange['-'] = df_add
df_add = pd.concat(dict_level_arange, axis=1).reorder_levels(list(range(1, levelnum+i+1))+[0], axis=1)
dict_items[key] = df_add
df_items = pd.concat(dict_items, axis=1)
if root is True:
df_items.index = [index_name]
df_items = df_items.droplevel(max_level, axis=1)
return df_items
使い方
基本的には以下のように辞書型オブジェクトを関数に与えてデータフレームを受け取る使い方をします。
df_output = NDtoMD(inputNDict)
以下はGoogleColablatory上で動作させた例です。入れ子の辞書型がマルチインデックス型のデータフレームとなっていることが分かります。’-‘はそのレベルの要素が存在しない場合に入ります。入れ子がリストの場合は、0, 1, 2,,,という連番のカラムになります。
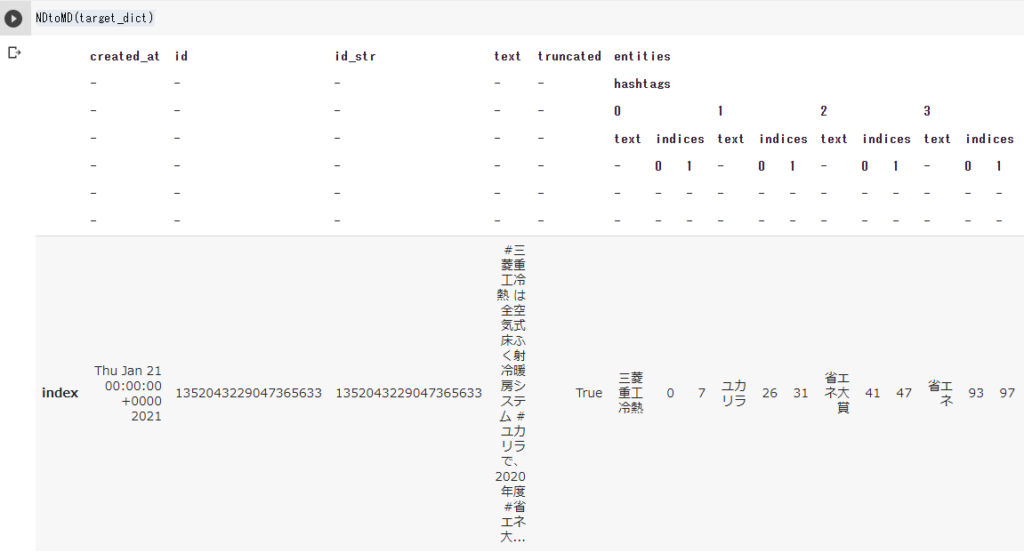
GoogleColablatoryの環境では、twitterAPIのjson構造の変換に要した時間が約300ms/レコードでした。もう少し早くできると使いやすい気はします。
%timeit NDtoMD(target_dict) 1 loop, best of 3: 308 ms per loop
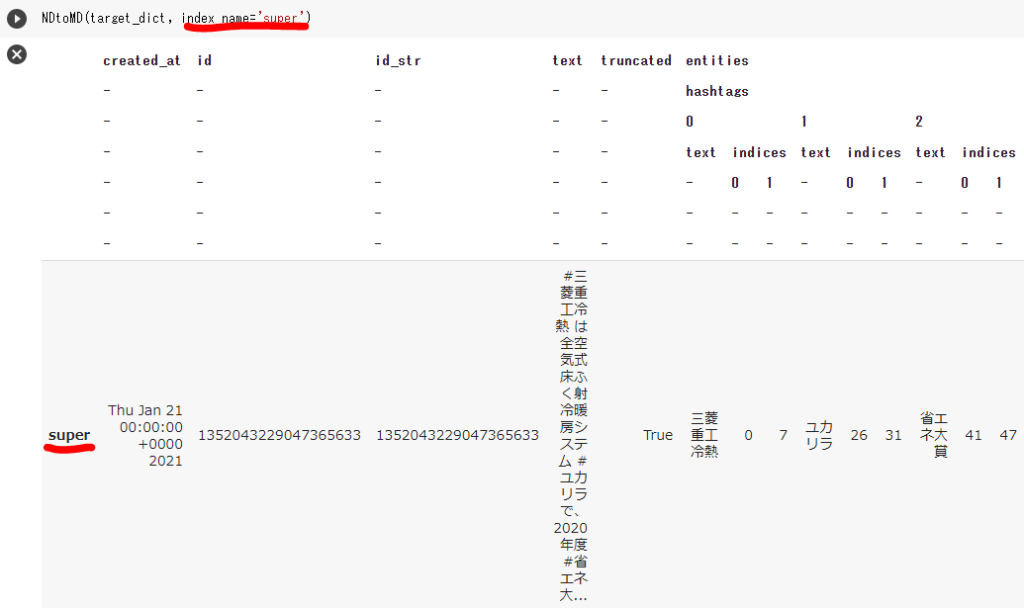
また、現在はindexの値が[index]になってますが、この値を変えたい場合はindex_nameを指定します。以下の例ではindexをsuperにしています。
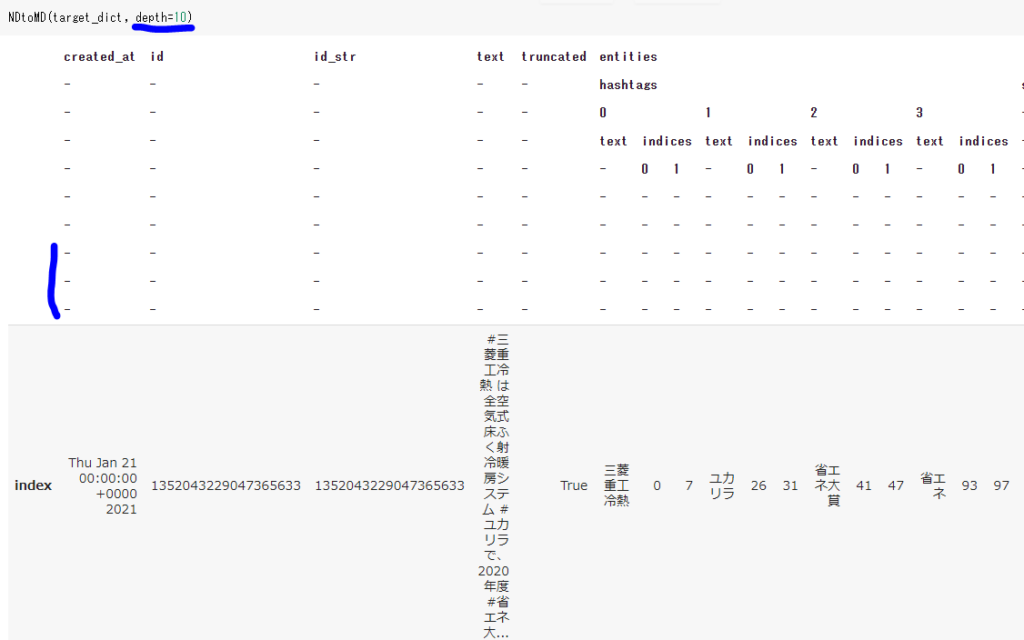
データレコードごとにレベルの違いがあると、変換後のconcatでエラーが出ます。その場合、大きいレベルに合わせておくことも考えられます。そんなときに使うのがdepthです。以下ではレベルを10にしています。
まとめ
入れ子のDictionary型をpandasのMultiIndex型で読み込んでくれる関数(NDtoMD)を作成・紹介しました。皆様の入れ子構造型のデータ分析に役立てれば幸いです。
if (root is True) & (depth is not None):の部分でSyntaxError: invalid syntaxとなってしまいます.
調べてもよくわからなかったのでご教示いただきたく存じます.
コードに文字化けが混ざっていて申し訳ございません。
文字化けについては修正し、修正後のコードをコピーして実行したところ、エラーは出ずに動作しました。
何故「SyntaxError: invalid syntax」が出たのかは私も分からないのですが、もう一度試してみていただけないでしょうか。