概要
pythonでデータ分析をする際にはpandasのDataframe型が有効ですが、扱うデータが複雑になってくると、indexとcolumnsの2次元だけでは足りず、3次元、4次元のデータを扱う必要が出てきます。
このような場合には、MultiIndexを用いることで多次元のデータを効率的に扱えるようになるのですが、公式ドキュメントには冗長な説明があったり、便利な方法の記載が省略されていたりと不十分感があると感じていました。
そこで本記事では、MultiIndexを使いやすくすることを目的に、取り扱いたいユースシーンを挙げながら、サンプルデータを対象に処理に必要なコードと結果を記載しました。なお、 pandasのバージョンは0.25.3を使っています。
MultiIndexのDataframeを扱う前に
どのような場合に有効か
概要欄にも記載した通り、MultiIndexが有効になるのは、3次元、4次元等の高次元のデータを扱いたいシーンです。一例ですが、データ分析であれば以下のような状況が挙げられます。
- 時系列のindexと計測項目のcolumnsからなる時系列データにいくつかの種類の前処理(例えば1時間の平均値や標準偏差等を算出)をし、さらに対象データの種類が複数ある場合
- 各種機械学習アルゴリズムを各種データに適用し、その評価をクロスバリデーションと複数の評価指標から行いたい場合
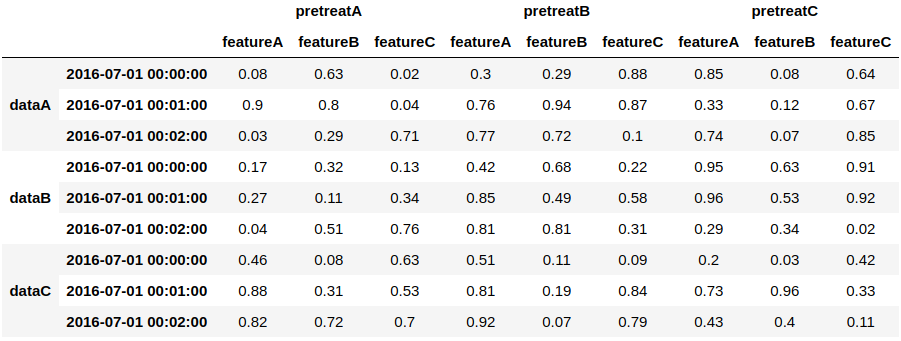
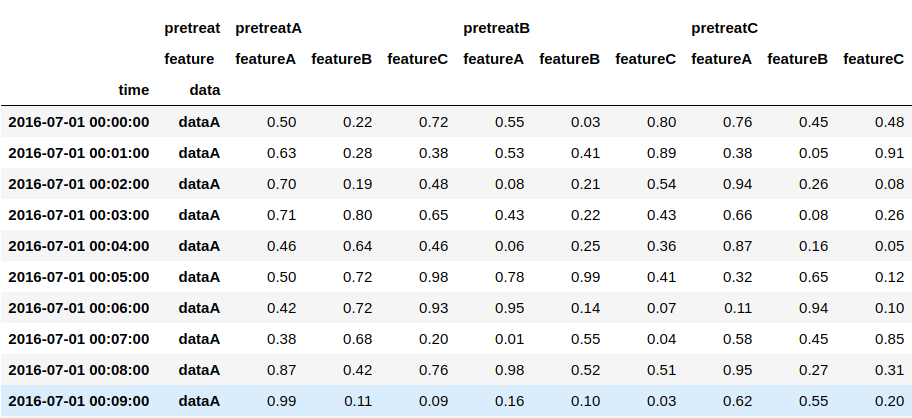
1の場合、例えばindexを対象データと時系列のMultiIndexに、columnsを前処理種類と計測項目のMultiIndexにそれぞれ設定した以下のようなDataframeで表すことが出来ます。
2の場合、例えばindexを各クロスバリデーションのデータと評価指標のMultiIndexに、columnsを各データと各アルゴリズムのMultiIndexにそれぞれ設定した以下のようなDataframeで表すことが出来ます。
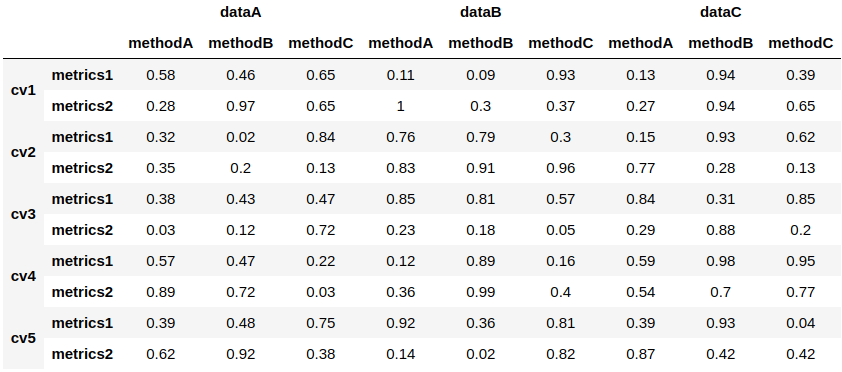
上記の例をみると、MultiIndexを使わずに表現する(例えば、dataA_methodAのような拡張性のないカラム名を作る)よりも、スマートにデータを表していると感じていただけると思います。
もちろん見た目だけの問題ではなく、後述するように組み合わせや順番を変えたり、演算をしたり、集計をしたりということも容易に可能ですので、高度な分析をするためにMultiIndexの活用は避けて通れないと考えています。
なお、上記の例ではどちらのサンプルもindexとcolumnsの其々をMultiIndexで2次元に対応させていますが、後述するように1つのMultiIndexに3次元以上を対応させたり、indexとcolumnsの其々の次元数を変えることも問題なく可能です。
定義方法
次にMultiIndexを定義する方法を説明します。これには、先にMultiIndexの内容を定義してからDataframeを作成して値を与えていく方法と、Dictionary型のitemとしてDataframeを与えて、concatで自動的にMultiIndexにする方法の2つがあります。個人的に、前者よりも後者のほうが覚えることが少なく、コーディングの効率も良いと感じています。
MultiIndexを明示的に定義して使う方法
pandasの公式ドキュメントには、MultiIndexを定義する方法として以下の関数を使った例が示されています。
- pd.MultiIndex.from_tuples
- pd.MultiIndex.from_product
- pd.MultiIndex.from_frame
- Dataframe.set_index
1と3と4は予めMultiIndexとなる配列を作っておき、それをMultiIndexにする方法です。1はtuple形式で、3はDataframeを与えて戻り値でMultiIndexを得るもので、4は既存のデータフレームから複数のカラムを指定してMultiIndex化されたDataframeを得るものです。記載はありませんが4と類似した方法としてpivot_tableを用いる方法もあります。
2は、MultiIndexの其々の要素を与えて、組み合わせを計算させてMultiIndexを得る方法です。サンプルデータ2の例では、以下のようなコードでMultiIndex化されたindexを得ることが出来ます。
#入力
import pandas as pd
pd.MultiIndex.from_product([['cv1', 'cv2', 'cv3', 'cv4', 'cv5'],
['metrics1', 'metrics2']],
names=['cv', 'metrics'])
#出力
MultiIndex(levels=[['cv1', 'cv2', 'cv3', 'cv4', 'cv5'], ['metrics1', 'metrics2']],
labels=[[0, 0, 1, 1, 2, 2, 3, 3, 4, 4], [0, 1, 0, 1, 0, 1, 0, 1, 0, 1]],
names=['cv', 'metrics'])
出力を見ると、MultiIndexは3つの項目(levels, labels, names)で構成されていることがわかります。これらはそれぞれ以下を表しています。
- levels
MultiIndexがどのような種類と要素の配列で構成されているかを示します。levelは0が1番に扱われ、1が時点、2以降と続いていきます。上の例で言えばlevel0としてcv1〜cv5の要素が、level1としてmetrics1, metrics2の要素があることを示しています。 - labels
Multiindexのそれぞれのindexがどの要素で構成されているかを示しています。上の例では[[0, 0, 1, 1,…], [0, 1, 0, 1,….]]とあるのでlevel0の要素が0(cv1), 0(cv1), 1(cv2), 1(cv2),…と並んでおり、level1の要素が0(metrics1), 1(metrics2), 0(metrics1), 1(metrics2)…と並んでいることを示しています。 - names
MultiIndexのそれぞれのlevelの名称を示しています。MultiIndexにはlevelの番号でアクセスする他に、この名称でアクセスすることが出来ます。上の例では[cv, metrics]が設定されていることを示しています。
MultiIndexを明示的に定義する方法では、最終的に使いたいDataframeを得るために、①MultiIndexの要素を予め定義し、②関数を呼び出してMultiIndexを作成し(1〜3の場合)、③それをindexに設定して新しいDataframeを作成し、④そのDataframeに値を書き込む場所を設定して値を代入していく必要があります。
実際のシーンでは、MultiIndexをいつも使うわけではないので②の関数名をなかなか覚えていられないのと、大抵基準となるDataframeは得られているので、そこから新しく必要な①と④のコーディングが特に面倒に感じる方が多いのではないでしょうか。そこで以下に示すもう一つの方法をご紹介したいと思います。
Dictionary型とconcatを用いて自動でMultiIndexを得る方法
この方法は以下のサイト(stack overflow)でも指摘されている方法です。
Dictionary of Pandas Dataframes to MultiIndex Dataframe
Nested dictionary to multiindex dataframe where dictionary keys are column labels
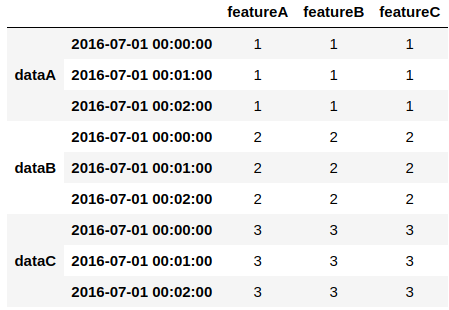
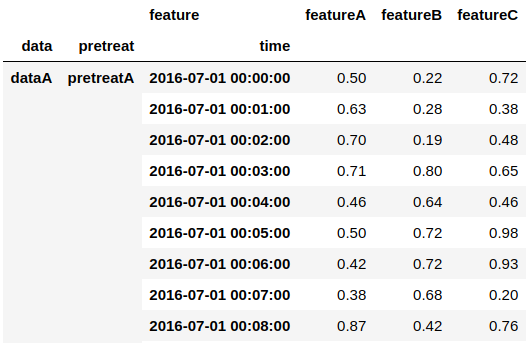
具体例として、df1〜df3というサンプルのDataframeを用意し、これらをdf_dictというdictionaryの要素として与えます。これをconcatすると以下図に示すようなMultiIndexのDataFrameを簡単に得ることが出来ます。
細かい比較はしませんが、MultiIndexの要素を定義する必要なく、普段使う関数だけを用いて、簡単なコードで目的のDataframeを得ることが出来るため、非常に利便性が高いと言えるでしょう。
#3つのデータフレームを用意
df1 = pd.DataFrame(index=pd.date_range('2016-07-01', periods=3, freq='T'),
columns=['featureA', 'featureB', 'featureC'],
data=1.0)
df2 = pd.DataFrame(index=pd.date_range('2016-07-01', periods=3, freq='T'),
columns=['featureA', 'featureB', 'featureC'],
data=2.0)
df3 = pd.DataFrame(index=pd.date_range('2016-07-01', periods=3, freq='T'),
columns=['featureA', 'featureB', 'featureC'],
data=3.0)
#辞書型データに其々を設定
df_dict = dict()
df_dict['dataA'] = df1
df_dict['dataB'] = df2
df_dict['dataC'] = df3
#concatしてMultiIndex化
df_multiindex = pd.concat(df_dict, axis=0)
サンプルデータの定義
Dictionaryから定義する方法を用いて、以下のサンプルデータを定義しておきます。
result_data = dict()
for data in ["dataA", "dataB", "dataC"]:
result_pretreat = dict()
for pretreat in ["pretreatA", "pretreatB", "pretreatC"]:
result_cv = dict()
#7日分のデータを1時間単位で作成
timedata = pd.DataFrame(index=pd.date_range('2016-07-01', periods=7*24*60, freq='T'), columns=['featureA', 'featureB', 'featureC'], data=pd.np.NaN)
#値は乱数としておく
timedata.values[:, :] = pd.np.random.rand(*timedata.shape).round(2)
result_pretreat[pretreat] = timedata
result_data[data] = pd.concat(result_pretreat, axis=1)
result = pd.concat(result_data, axis=0)
#concatだとnamesがNoneになるためrename_axisで設定
result = result.rename_axis(['data','time'], axis=0).rename_axis(['pretreat','feature'], axis=1)
なお、時系列データの生成は以下を参考にしてます。
Generate time series of random numbers then down sample
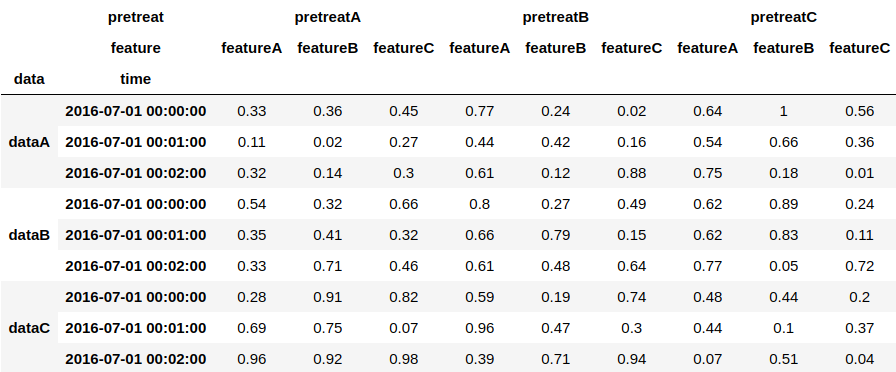
得られたデータはこちら。次章ではこのデータを用いて主要操作の説明をしていきます。
MultiIndexデータの主要操作
データアクセス
Dataframeにilocやlocでアクセスするには、pandasのIndexSliceを使うことが簡単だと思います。
idx = pd.IndexSlice
これを使ない方法では、例えばpretreatAのfeatureAにアクセスしようとして以下のようなコードを叩いてもすべてエラーが出ます。
#やりがちな入力 result.loc[:, :, 'pretreatA', 'featureA'] result.loc[:, ['pretreatA', 'featureA']]
#エラー IndexingError: Too many indexers
idxを使う方法は例えば以下です。スライシングも可能です。
#idxを使ったアクセス result.loc[:, idx['pretreatA', 'featureA']] #sliceを使う場合 result.loc[:, idx[:, 'featureA']]
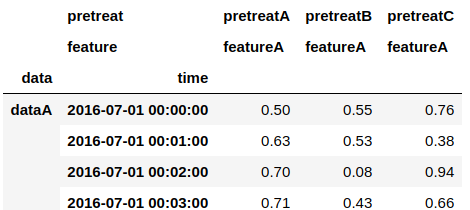
ただし、idxを使ってスライシングした場合、上記のようにcolumnsのlevel[1]がすべて同じ値のまま残ってしまいます。これを除外したいときは以下のようなコードを使います。
#droplevelをするとそのレベルのindexを消すことが出来る。 #古いバージョンだと実装されておらず、columnsやindexの後にdroplevelする必要がある模様。 result.loc[:, idx[:, "featureA"]].droplevel(level='feature', axis=1)
データ形状の調整方法
次に一度作ったDataframeの形状を調整する方法を説明します。
transpose処理
transposeというのは正式名称ではありませんが、このキーワードだと関連情報がヒットしやすかったのでtransposeという名称を使います。やりたいことは、indexの一部をcolumnsに回したり、その逆をしたり、levelを入れ替えたりといった処理を指します。
columnsのlevelをindexに移動
#stackを使うと、指定したlevelのカラムがindexに移動する。 result.stack(level="pretreat") result.stack(level=0) #又は数値で指定
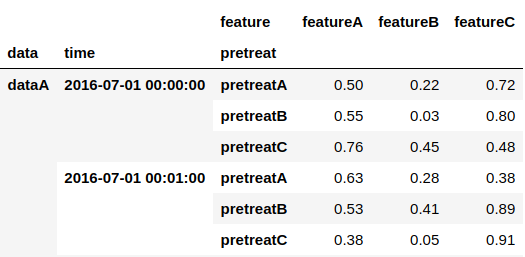
#複数を指定してstack result.stack(level=["pretreat", "feature"]) result.stack(level=[0, 1]) #又は数値で指定
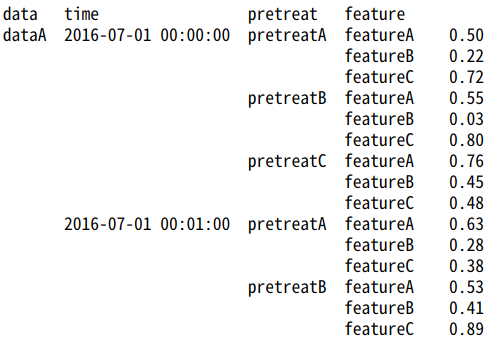
#全部を指定してstack result.stack(level=result.columns.names) result.stack(level=list(range(result.columns.nlevels))) #又は数値で指定
indexのlevelをcolumnsに移動
#unstackを使うと、指定したlevelのカラムがcolumnsに移動する。 result.unstack(level="data") result.unstack(level=0) #又は数値で指定
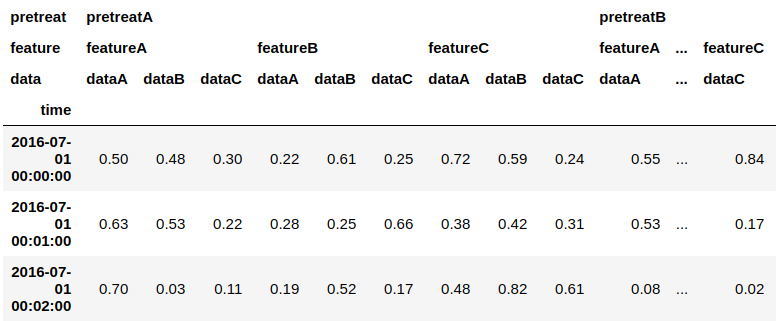
#複数を指定してunstack result.unstack(level=["data", "time"]) result.unstack(level=[0, 1]) #又は数値で指定
#全部を指定してunstack result.unstack(level=result.index.names) result.unstack(level=list(range(result.index.nlevels))) #又は数値で指定
levelの順番を入れ替え
levelの順番を入れ替えるにはreorder_levelsを使います。変更したいlevelsの順番とaxisを指定して使います。
#indexをtime,dataのlevel順に変更 result.reorder_levels(['time', 'data'], axis=0) result.reorder_levels([1, 0], axis=1) #又は数値で指定
#columnsをpretreat,featureのlevel順に変更 result.reorder_levels(['feature', 'pretreat'], axis=1) result.reorder_levels([1, 0], axis=1) #又は数値で指定
sort処理
sortは通常のDataframeと同様にsort_indexが使えます。levelとaxisを指定して使う感じです。
#reorderした後、timeでsort result.reorder_levels(['time', 'data'], axis=0).sort_index(level='time', axis=0)

#stackやreoder_levelsとの合わせ技 result.stack(level='pretreat').reorder_levels(['data', 'pretreat', 'time'], axis=0).sort_index(level=['data', 'pretreat'], axis=0)
meanやresample等の集計処理
データへのアクセス、形状調整までを抑えられたので、引き続き集計処理に入ります。この時、時系列を対象にした集計をする場合には少し手間が必要です。
時系列以外を集計する場合
この場合はmeans等の関数の引数にlevelを指定すればやりたい処理が出来ます。
#dataに関する平均とfeatureに関する平均を計算 result.mean(level='data', axis=0).mean(level='feature', axis=1) #timeに関する最小とfeatureに関する平均を計算 result.min(level='time', axis=0).min(level='feature', axis=1)
時系列を集計する場合
単純にresampleにlevelを指定すると、それ以外のlevelの情報も含めた処理をしてしまいます。
#resampleにlevelを指定
result.resample('1h', level=1).mean()
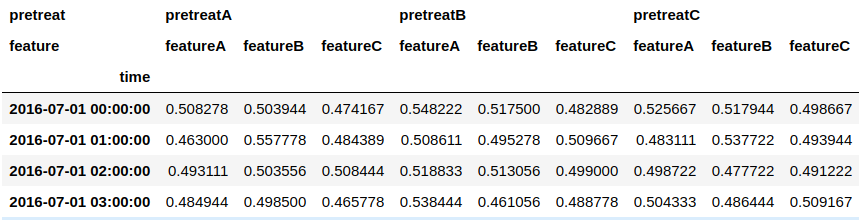
これを防ぐためには、一旦unstackしてからresampleし、stackで戻すという処理が必要です。
#時系列だけにしてからresamle
result.unstack('data').resample('1h', level=0).mean().stack('data')
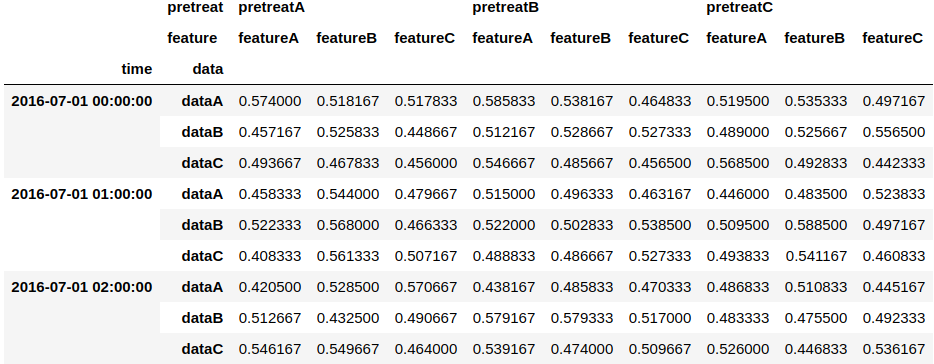
interpolateやrolling等の時系列特有の処理をしたい場合にも、このような手順で処理をすることで欲しい結果を得ることが可能です。また、時系列データではなくても、idxmaxのようにlevelを引数に取れない関数の場合には同様の処理が有効になります。
addやmul等の演算処理
Dataframeを作ってから、例えばfeatureAは2倍、featureBはそのまま、featureCは0倍するような処理をしたくなったとします。このデータ例では適切ではないかもしれませんが、重み付け和を取りたい場合などが該当すると思います。
このような場合、掛け算をするmulと、これまでのunstack等を組み合わせることで処理が出来ます。
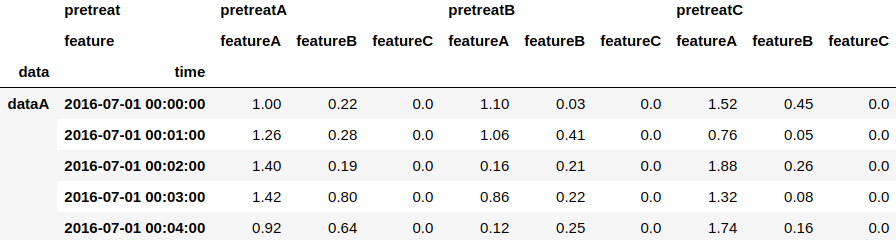
#featureAを2倍、featureBを1倍、featureCを0倍する
result.stack(level='pretreat').mul([2, 1, 0]).unstack('pretreat')

上記を見ると、少なくともfeatureCが0倍になっていることは確認できます。featureとpretreatの並びが変わってしまっているのは、reorder_levelsとsort_indexで元に戻すことが出来ます。
#featureAを2倍、featureBを1倍、featureCを0倍する
#並びも元に戻す
result.stack(level='pretreat').mul([2, 1, 0]).unstack('pretreat')\
.reorder_levels(['pretreat', 'feature'], axis=1).sort_index(level='pretreat', axis=1)
ここではmulを紹介しましたが、addやsub、divでも同様の処理が可能です。
MultiIndexの解除
何らかの理由でMultiIndex化したDataframeのindexを元に戻したい場合は、reset_indexを使うことで通常のDataframeに変換することが出来ます。
#indexのMultiIndexをreset result.reset_index() #columnsのMultiIndexをreset result.T.reset_index()
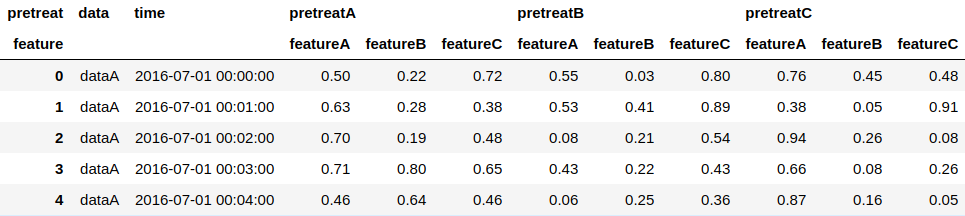
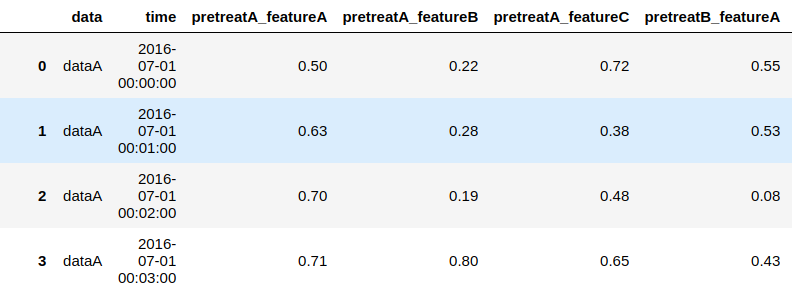
indexとcolumnsの両方がMultiIndexの場合はresetできないので、columnsの名称をpretreatA_featureAのような表現にして対応します。
Reset a column’s MultiIndex levels
#columnsを書き換え result.columns = ['_'.join(col) for col in result.columns] #indexのMultiIndexをreset result.reset_index()
まとめ
本記事ではpandasのMultiIndexを使いこなすための要件として、以下を取り上げてサンプルコードと共に記載しました。
- MultiIndexを使ったDataframeの作成方法
- 要素へのアクセス方法
- Dataframe形状の調整方法
- データの集計・演算方法
- MultiIndexの解除方法
これらの内容が皆様のPythonライフに役立てば何よりです。
素晴らしい記事でした!培養センサーデータ解析に取り組んでおり、MultiIndexの扱いに四苦八苦していました。
超絶汚いコードで作っていたものが大分すっきり整理できそうです。参考にさせていただきます。
MultiIndex分かりにくいですが便利ですよね。コメント、とても励みになります!
めちゃめちゃ助かりました。
コメントありがとうございます!お役に立てて何よりです!