概要
Pythonにはseabornという多機能で綺麗なグラフを描くライブラリがあります。このseabornの全メソッドの効果を検証したのが今回の記事です。サンプルデータとしてirisとtitanicを使って説明していきます。
#seabornはsnsという名前で使う
import seaborn as sns
if __name__ == "__main__":
#irisデータをdfに格納
df = sns.load_dataset("iris")
#titanicデータをdf2に格納
df2 = sns.load_dataset("titanic")
メソッド一覧
コンソール上でdir(sns)と入力すると、メンバの一覧が取得できます。その中でメソッドを抽出すると以下大量の77メソッドがあることが分かります。本記事(その1)では、誰もが気になる、グラフを書くためのメソッド(全24:水色塗)を検証し、seabornで描ける全グラフを確認しました。
| FacetGrid | JointGrid | PairGrid | algorithms |
| axes_style | axesgrid | barplot | blend_palette |
| boxplot | categoriacl | choose_colorbrewer_palette | choose_cubehelix_palette |
| choose_dark_palette | choose_diverging_palette | choose_light_palette | clustermap |
| coefplot | color_palette | countplot | crayon_palette |
| crayons | cubehelix_palette | dark_palette | desaturate |
| despine | distplot | distributions | diverging_palette |
| division | external | factorplot | get_dataset_names |
| heatmap | hls_palette | husl_palette | interactplot |
| jointplot | kdeplot | light_palette | linearmodels |
| lmplot | load_dataset | lvplot | matrix |
| miscplot | mpl | mpl_palette | np |
| pairplot | palettes | palplot | plotting_context |
| plt | pointplot | puppyplot | rcmod |
| regplot | reset_defaults | reset_orig | residplot |
| rugplot | saturate | set | set_color_codes |
| set_context | set_hls_values | set_palette | set_style |
| stripplot | swarmplot | timeseries | tsplot |
| utils | violinplot | widgets | xkcd_palette |
| xkcd_rgb |
Distribution plots
API紹介の公式ページでの分類分けを踏襲し、説明していきます。まずはデータ分布を可視化する(Distribution plots)メソッドです。
jointplot
2変数間の分布を可視化するグラフ。引数のkindを与えることで複数のグラフが描ける。residを指定した場合を除き、さりげなく相関係数とp値も表示される。
scatter
デフォルトか、kindで”scatter”を指定した場合。scatterグラフだけでなく、それぞれのヒストグラムも表示されており利便性は高そう。
sns.jointplot(df.columns[0], df.columns[1], df)
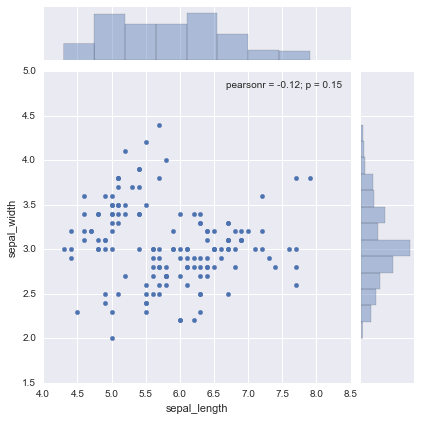
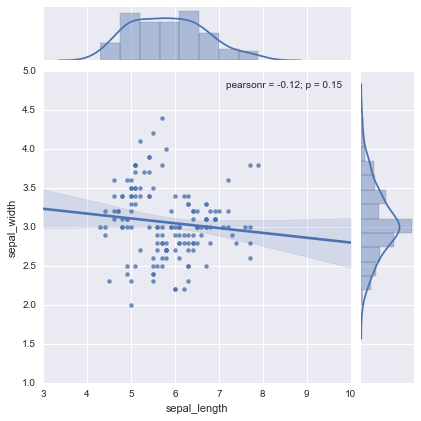
reg
kindで”reg”を指定した場合。線形回帰線が追加される。
sns.jointplot(df.columns[0], df.columns[1], df, kind="reg")
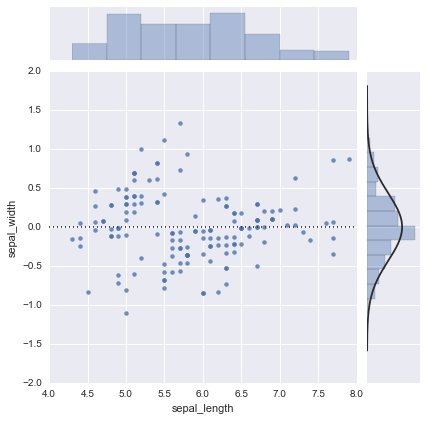
resid
kindで”resid”を指定した場合。分布を表す|が追加されているが、あまり良くわからない。
sns.jointplot(df.columns[0], df.columns[1], df, kind="resid")
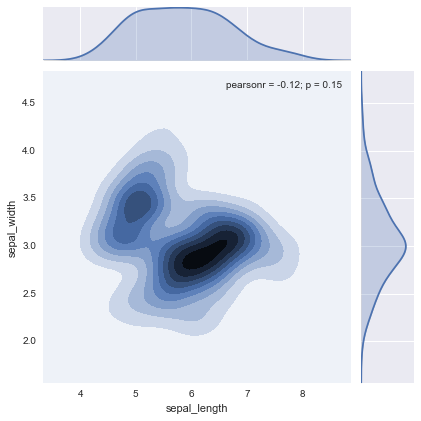
kde
kindで”kde”を指定した場合。等高線が表示される。
sns.jointplot(df.columns[0], df.columns[1], df, kind="kde")
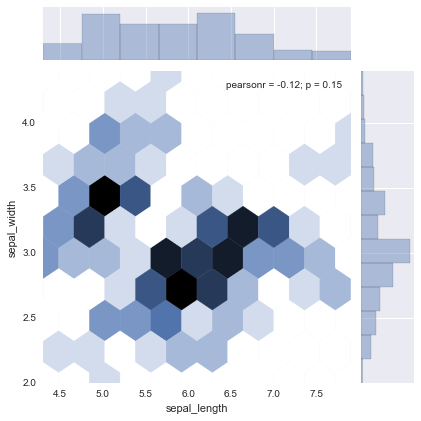
hex
kindで”hex”を指定した場合。独特の表現。
sns.jointplot(df.columns[0], df.columns[1], df, kind="hex")
pairplot
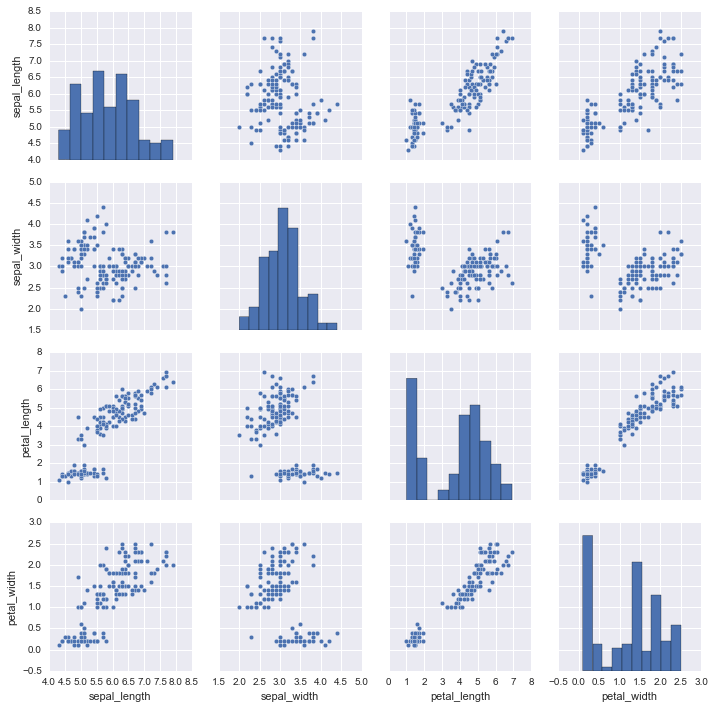
多変数間の分布を可視化するグラフ。hueにカテゴリ変数を指定すると色分けされたグラフが描け非常に有効。また、kindやdiag_kindの指定でグラフの形状を変えることができる。
sns.pairplot(df)
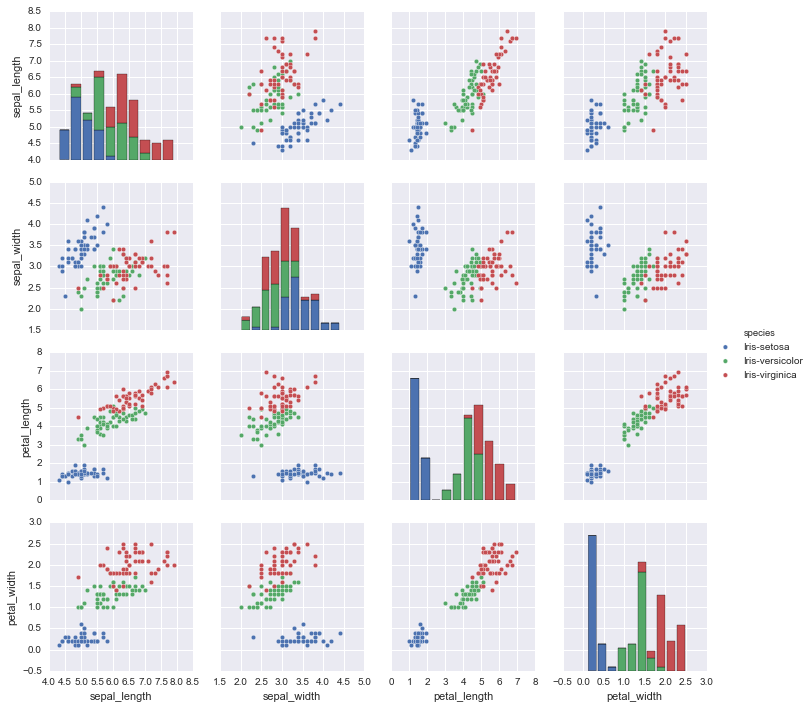
#hueを指定することでカテゴリごとに色分けされる。 sns.pairplot(df, hue='species')
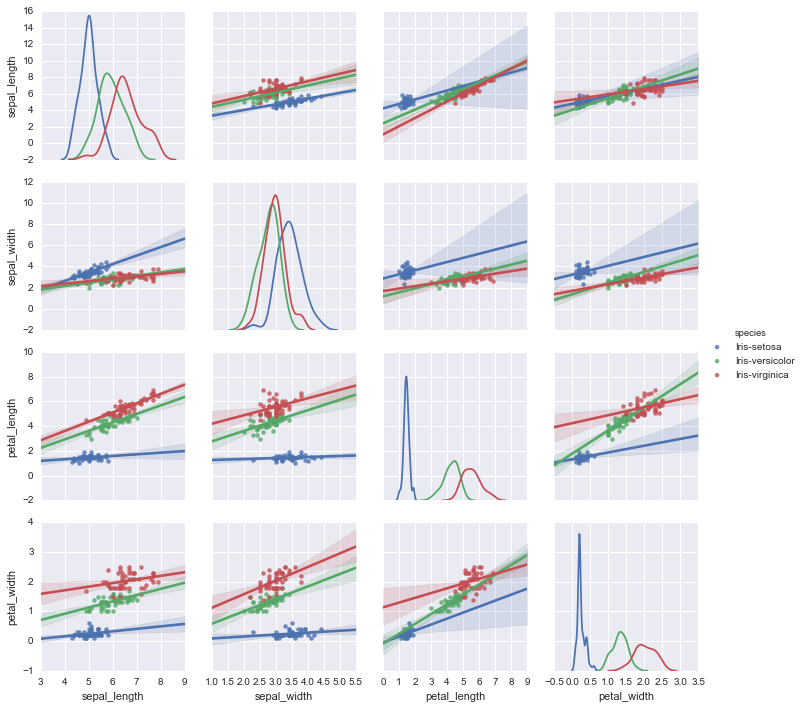
#kindとdiag_kindを指定すると形状を変えられる。 sns.pairplot(df, hue='species', kind='reg', diag_kind='kde')
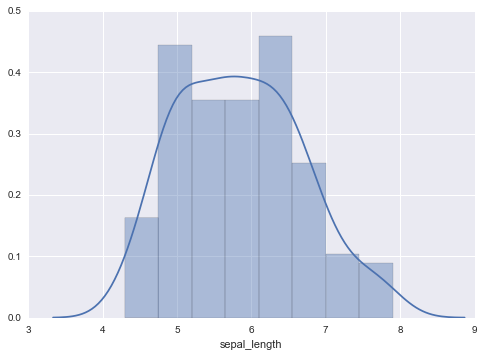
distplot
1変数の分布を可視化する。
sns.distplot(df[df.columns[0]])
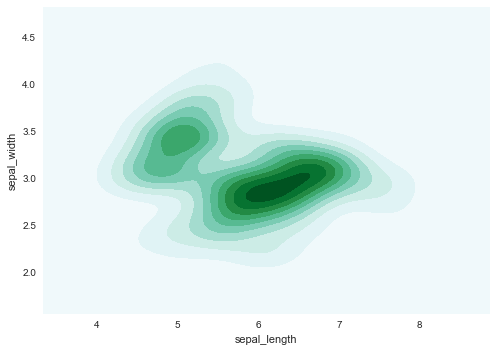
kdeplot
1変数又は2変数の分布をkdeで可視化する。
sns.kdeplot(df[df.columns[0]], df[df.columns[1]], shade=True)
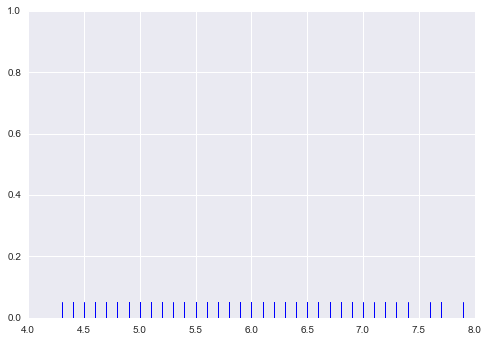
kdeplot
1変数の分布をrugで可視化する。
sns.rugplot(df[df.columns[0]])
Regression plots
主に連続変数を可視化する(Regression plots)メソッドです。
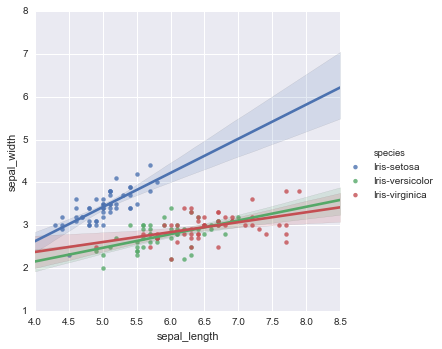
lmplot
2変数間の散布図と線形回帰線を可視化するグラフ。hue, col, rowにはカテゴリ変数を指定でき、hueを指定すると色分け、colやrowを指定するとmatrix的にデータをプロットできる。数値データとカテゴリデータが混在する時にかなり有効に使えそう。
#色分け sns.lmplot(df.columns[0], df.columns[1], df, hue="species")
#列方向に並べて表示 sns.lmplot(df.columns[0], df.columns[1], df, col="species")
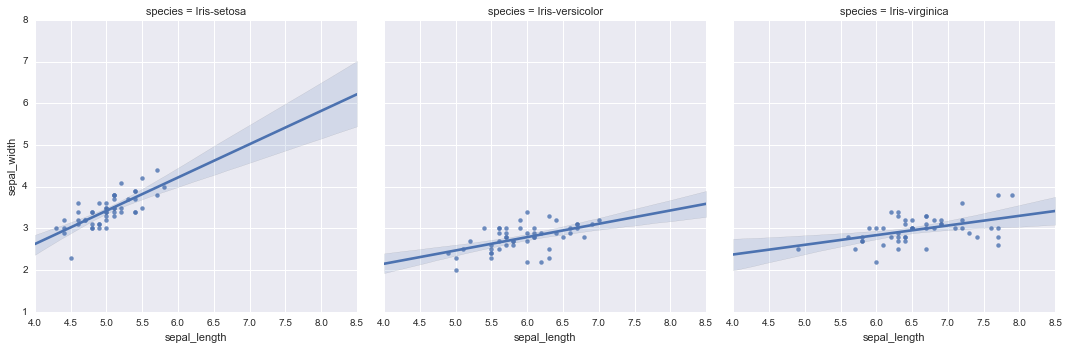
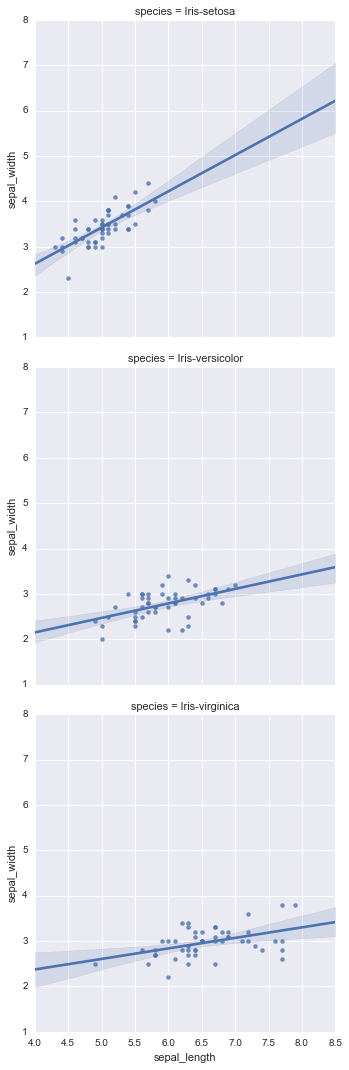
#行方向に並べて表示 sns.lmplot(df.columns[0], df.columns[1], df, row="species")
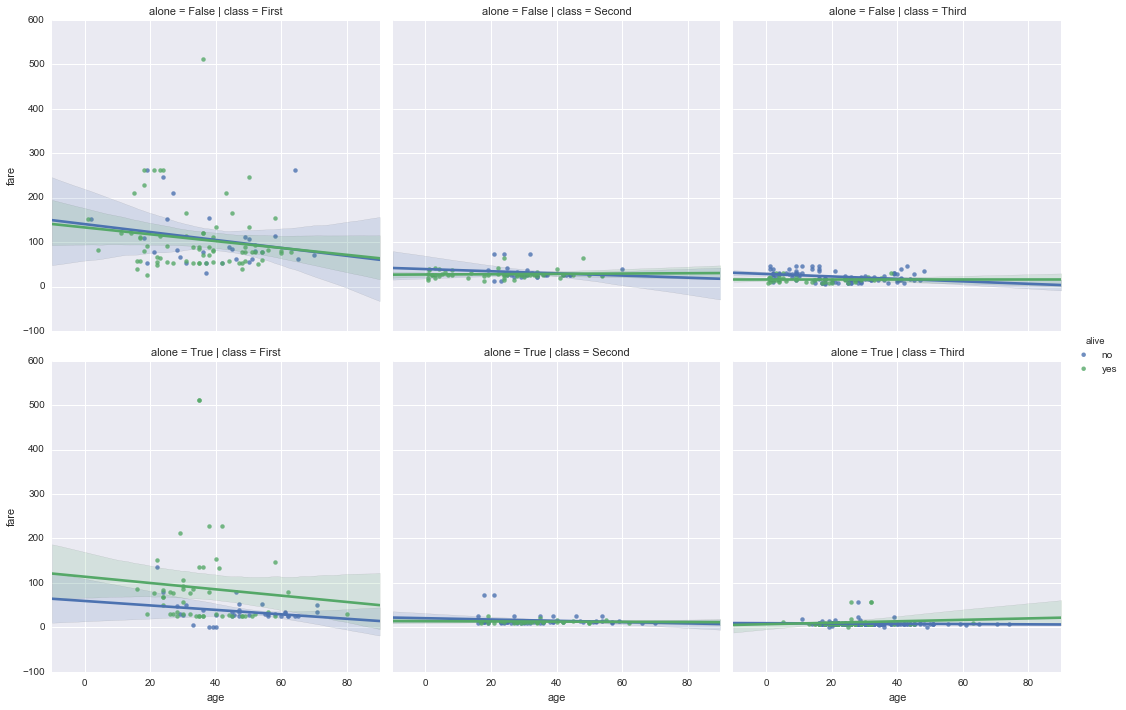
#カテゴリ変数が多い場合は特に有効 sns.lmplot(x='age', y='fare', data=df2, hue='alive', col='class', row='alone')
regplot
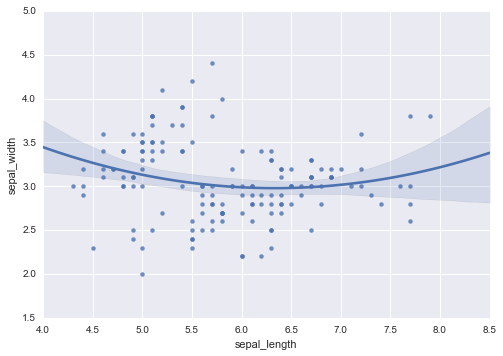
2変数間の散布図と近似線を可視化するグラフ。orderの指定で多項式を、logisticの指定でロジスティック関数を近似に用いることができる。
#多項式の次数を2に指定 sns.regplot(df.columns[0], df.columns[1], df, order=2)
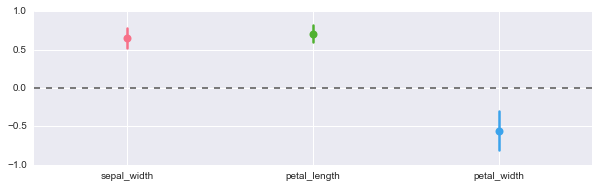
residplot
2変数間の散布図とresid valueを可視化するグラフ。residとは残余価値を示し、資産運用等に使う指標とのこと。ヘルプにはIdeally, these values should be randomly scattered around y = 0と書いてあり、0付近にあればいいらしい。ところで、何がいいんだろう?(笑)
#多項式の次数を2に指定 sns.regplot(df.columns[0], df.columns[1], df)
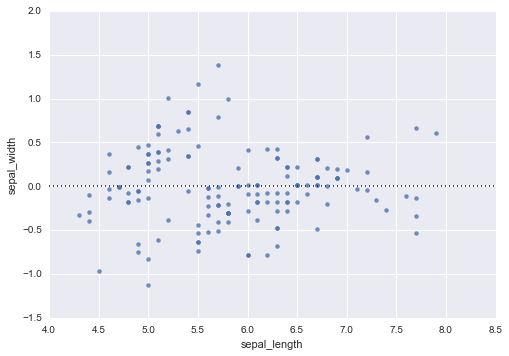
interactplot
3変数を使ってコンタ図を描くことができる。
sns.interactplot(df[df.columns[0]], df[df.columns[1]], df[df.columns[2]])
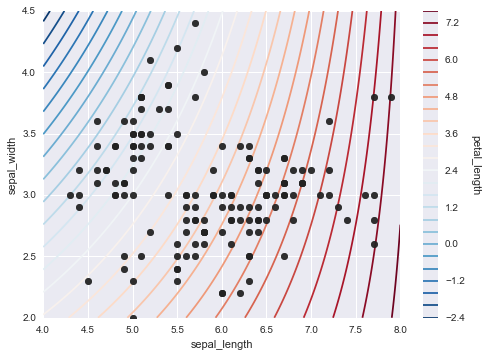
coefplot
変数間の線形関係係数を計算し描くことができる。線形関係係数ってなんでしょう?
プロットした感じ相関係数っぽいのですが、ちょっと違いそうです。尚、使い方が全然わからず、私的メモさんの記事を参考にさせて頂きました。(これは初見では分からない。。。)
#~以前の変数と以後の間の変数の線形関係係数を演算し描画する sns.coefplot(df.columns[0] + "~" + df.columns[1] + "+" + df.columns[2] + "+" + df.columns[3], df)
Categorical plots
主に離散変数を可視化する(Categorical plots)メソッドです。
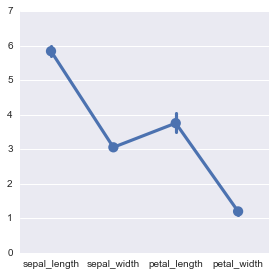
factorplot
複数の離散変数と1つ以下の連続変数の分布を可視化するグラフ。violinplot等、かなりユニークなものが多いが、可視化効果は高そうなのでなんとか使いこなしたいところ。引数のkindを与えることで複数のグラフが描ける。
point
デフォルトか、kindで”point”を指定した場合。
sns.factorplot(data=df, kind='violin', col='species')
#指定するカテゴリ変数の量が多いほど可視化効果が高い sns.factorplot(x='class', y='age', data=df2, hue='alive', col='sex', row='alone')
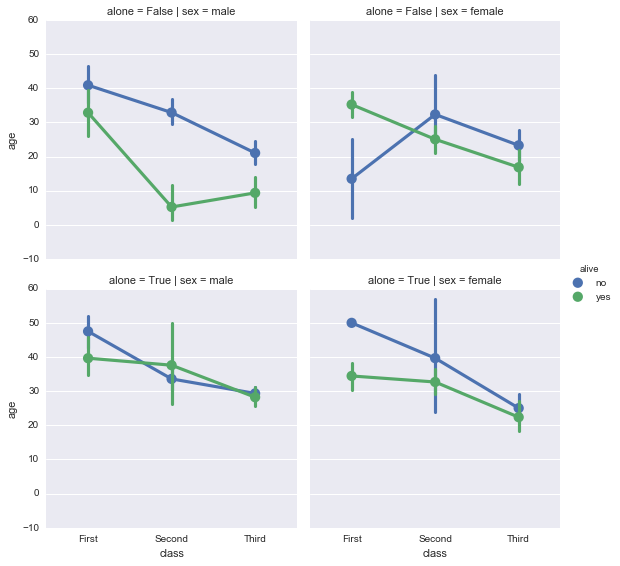
bar
kindで”bar”を指定した場合。
sns.factorplot(x='class', y='age', data=df2, hue='alive', kind='bar', col='sex', row='alone')
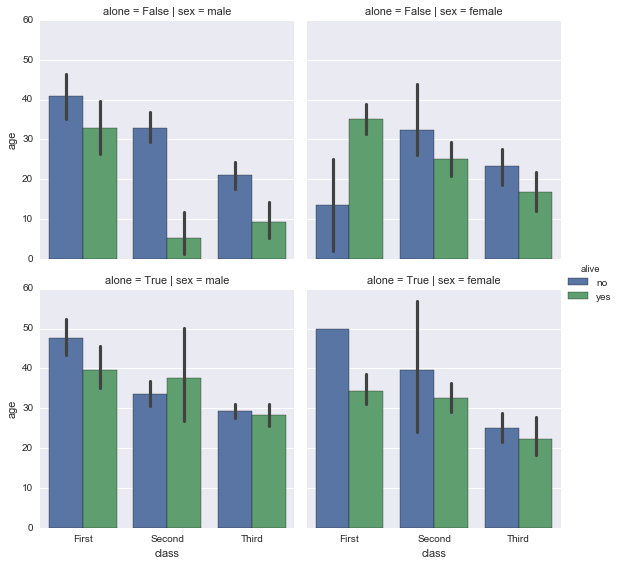
count
kindで”count”を指定した場合。カテゴリ変数を組み合わせた場合のデータ個数の可視化に有効。
sns.factorplot(x='class', data=df2, hue='alive', kind='count', col='sex', row='alone')
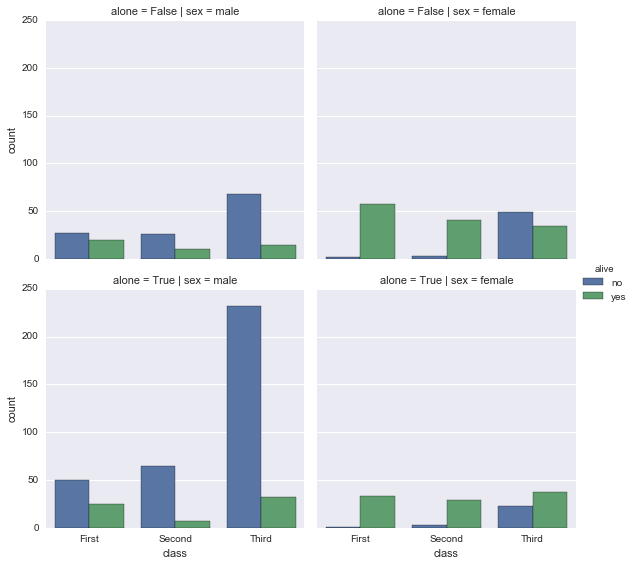
box
kindで”box”を指定した場合。いわゆる箱ひげ図。
sns.factorplot(x='class', y='age', data=df2, hue='alive', kind='box', col='sex', row='alone')
lv
kindで”lv”を指定した場合。箱ひげが立体的になった感じの図。
sns.factorplot(x='class', y='age', data=df2, hue='lv', kind='box', col='sex', row='alone')
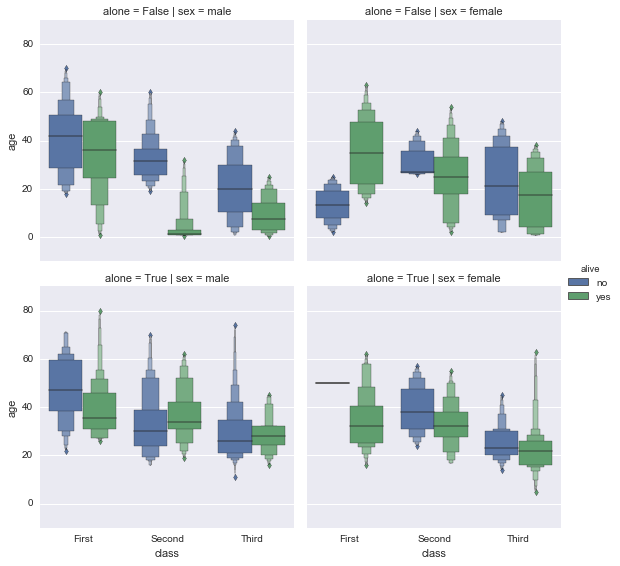
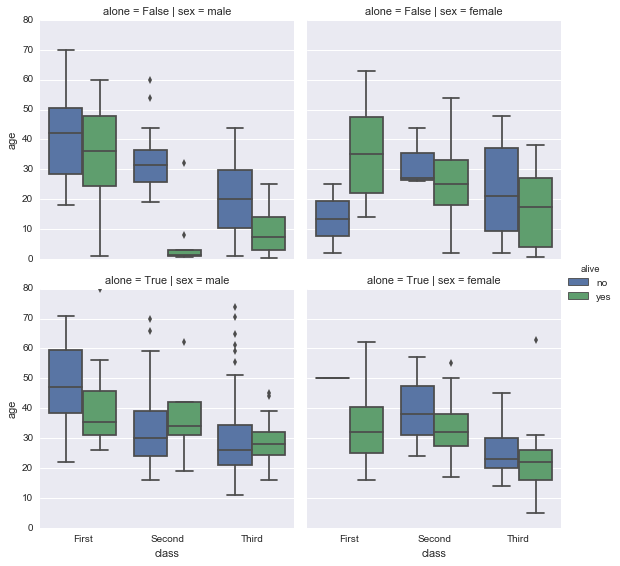
violin
kindで”violin”を指定した場合。見慣れないグラフだが、変数のデータの分布がよくわかるためおススメ。
sns.factorplot(x='class', y='age', data=df2, hue='alive', kind='violin', col='sex', row='alone', split=True, inner="quartile")
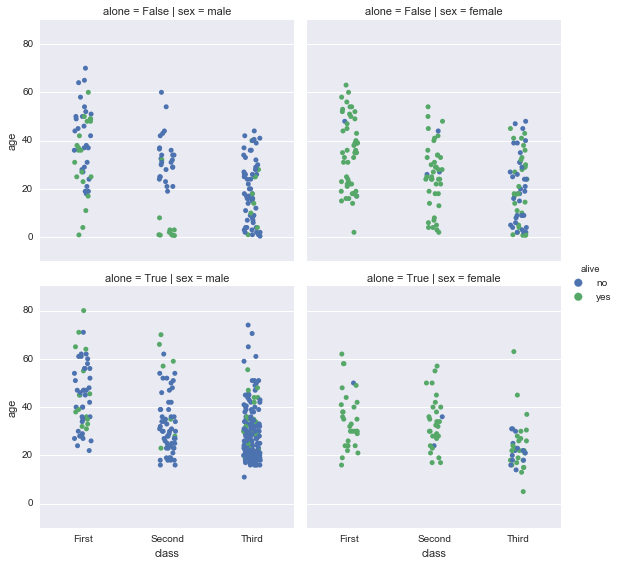
strip
kindで”strip”を指定した場合。
sns.factorplot(x='class', y='age', data=df2, hue='alive', kind='strip', col='sex', row='alone', jitter=True)
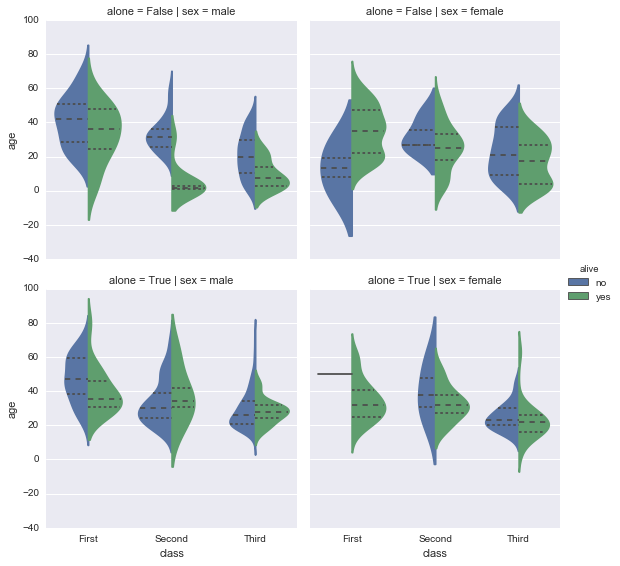
swarm
kindで”swarm”を指定した場合。violinとstripの中間のような位置づけ。
sns.factorplot(x='class', y='age', data=df2, hue='alive', kind='swarm', col='sex', row='alone')
boxplot, violinplot, stripplot, swarmplot, pointplot, barplot, countplot, lvplot
factorplotでkindを指定した場合と変わらなかったため割愛。
Matrix plots
カラム間又はインデック間を可視化する(Matrix plots)メソッドです。
heatmap
データの大きさで色分けするグラフ。相関関係等の可視化に非常に有効。
sns.heatmap(df.corr())

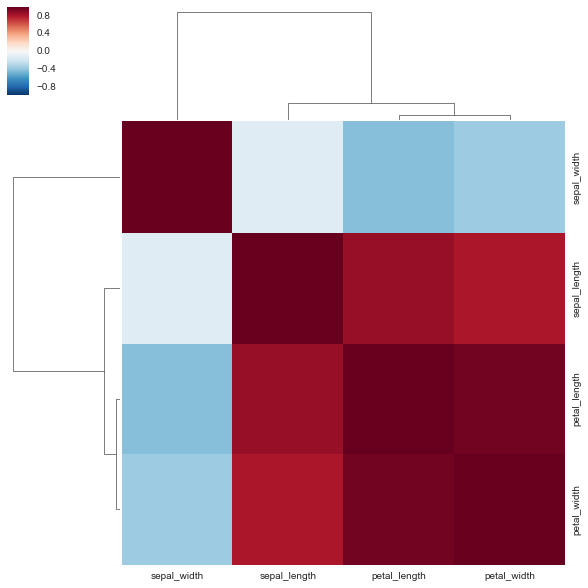
clustermap
heatmapの要素に加え、階層型クラスタリングを実施しデンドログラムまで作成する。こちらも相関関係等の可視化に非常に有効。
sns.clustermap(df.corr())
その他
上記に含まれないメソッドです。
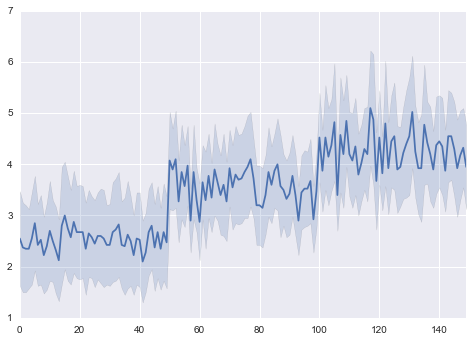
tsplot
複数のカラムのデータを与えた時に、ばらつき度合いを含めたプロットをしてくれる。
sns.tsplot(np.array(df[df.columns[0:4]].T))
palplot
パレットを描画する。この方のサイトを参考にしました。
sns.palplot(sns.color_palette(n_colors=6))

sns.palplot(sns.hls_palette(24))

puppyplot
動かないし、ヘルプに何も書いていない。実態不明。
まとめ
その1ではseabornの全プロットメソッドについて紹介しました。個人的には多項式近似のregplot、ユニークなviolinplot、コンタ図が描けるinteractplot、クラスタリングまで実施してくれるclustermapが特に使えると感じました。その2以降で残りのメソッドも検証していく予定です。