概要
予測に影響した特徴量の重要度を可視化できるライブラリとしてSHAPが存在感を増しています。SHAPは SHapley Additive exPlanations を指しており、 Wikipediaによると、SHapley は人の名前から来ていて、ゲーム理論で用いられる「協力により得られた報酬をどのようにプレイヤーに配分するか」という問題に対する考え方ということです。
SHAP は機械学習の手法を問わず使うことができ 非常に便利であるという噂を耳にしたため、本記事では SHAP の全メソッドを試して効果を検証してみました。 なお、 SHAP のバージョンは0.30.2を使っています。
インストール方法と簡単な使い方説明
他のライブラリ同様、pipの処理で可能です。 自分はimport時に「ModuleNotFoundError: No module named ‘tqdm.auto’」のエラーが出ましたが、以下URLを参考にtqdmをアップデートしたら解決しました。
https://github.com/nteract/papermill/issues/287
pip install shap pip install -U tqdm
SHAPの基本的な使い方は以下の通りです。
- sklearn等を用いて学習済みモデルのオブジェクトを用意しておく
- SHAPのExplainerに学習済みモデル等を渡して SHAP モデルを作成する
- SHAPモデルのshap_valuesメソッドに予測用の説明変数を渡してSHAP値を得る
- SHAPのPlotsメソッド (force_plot等)を用いて可視化する
スクリプトで見ていきましょう。irisのデータをサンプルに動作コードを記載しました。
import shap
from sklearn.ensemble import RandomForestClassifier
#irisのデータを使うこととする。
iris_X, iris_y = shap.datasets.iris()
#RandamForestの学習済みモデルを用意する。
clf = RandomForestClassifier().fit(iris_X, iris_y)
#SHAPのExplainerを用意する。ランダムフォレストなのでTreeExplainerを使う。
explainer = shap.TreeExplainer(clf)
#irisの最初のデータを例にshap_valuesを求める。
shap_values = explainer.shap_values(iris_X.loc[[0]])
#予測に使ったデータに対してsetosaとなる確率とその要因について可視化する。
shap.force_plot(explainer.expected_value[0],
shap_values[0],
iris_X.loc[[0]],
matplotlib=True,
)
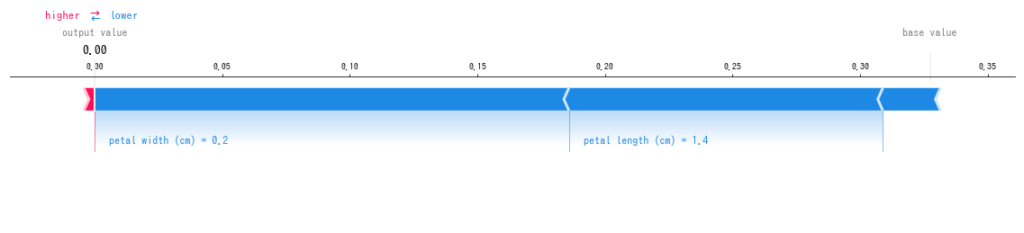
上記を実行すると以下のような画像が得られ、irisの1番目のデータの予測結果はsetosaである(1.00)という結果で、その要因はpetal lengthが1.4cmであることや、petal widthが0.2cmであることが主要因であるとしています。irisのデータを知っていると、これが正しい結果だとわかりますね。
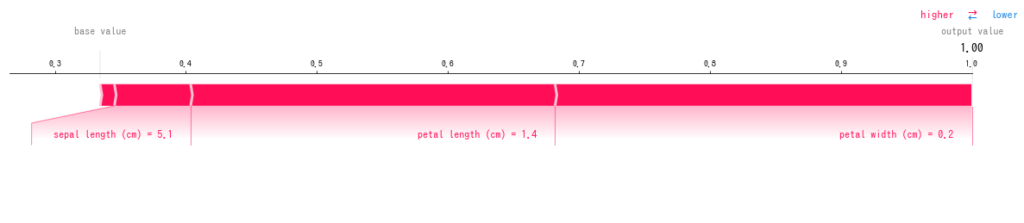
本例では、RandomForestClassifierを対象にしていますが、RegressorやそのほかのモデルでもSHAPを動作させて、同様の結果を得ることが可能です。
メソッド一覧
SHAPのドキュメントのページには以下の7つのメソッドが記載されており、これらを対象に検証していきます。
| TreeExplainer | KernelExplainer | DeepExplainer | summary_plot |
| dependence_plot | force_plot | image_plot |
TreeExplainer
TreeExplainerは決定木系のアルゴリズムのSHAP値を効率的に求めるためのクラスで、サンプルで説明したように引数にモデルを渡す必要があります。
explainer = shap.TreeExplainer(clf)
このモデルにはsklearnモデルの木構造系の分類や回帰の他、Xgboostやlightgbm等のモデルも用いることができます。
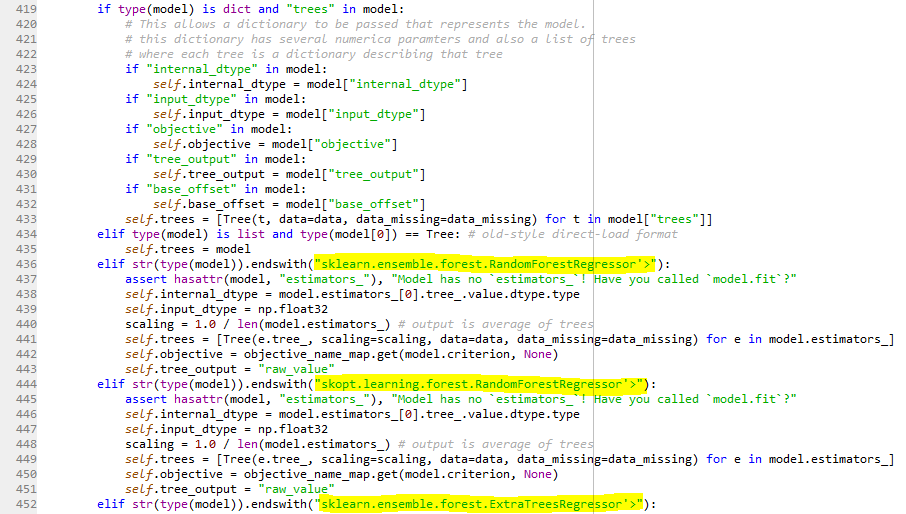
どうなっているのだろうとスクリプトを追っていくと、tree.pyの中にモデルを識別するためのTreeEnsembleという関数があり、そこでは以下の黄色塗り部分ように、if文を用いた条件分岐でモデルの種類を確認して読み込み処理をする作りになっていました。ですので、何でも使えるわけではないですが、有名どころはほぼ使えるという具合になっているようです。
ロジックも簡単に追いかけて資料にまとめてみました。
https://www.slideshare.net/KazuyukiWakasugi/shap-181632545
KernelExplainer
KernelExplainerはアルゴリズムを問わず用いることができるクラスで、モデルとデータを渡して使います。データを渡すのは、そのデータを使ってSHAP値を計算するモデルを構築するためとのことです。下記ではSVMを用いた例でモデルを定義しています。
import shap
from sklearn.svm import SVC
#irisのデータを使うこととする。
iris_X, iris_y = shap.datasets.iris()
#SVCの学習済みモデルを用意する。
clf = SVC().fit(iris_X, iris_y)
#SHAPのExplainerを用意する。SVCなのでKernelExplainerを使う。
explainer = shap.KernelExplainer(clf.predict, iris_X)
#irisの最初のデータを例にshap_valuesを求める。
shap_values = explainer.shap_values(iris_X.loc[[0]])
#予測に使ったデータに対して出力とその要因について可視化する。
shap.force_plot(explainer.expected_value,
shap_values,
iris_X.loc[[0]],
matplotlib=True,
)
注意する点としては、TreeExplainerのように内部でどのライブラリのモデルかを識別するようなことはできないため、引数として渡すのはモデル(clf)ではなく、具体的な予測のメソッド(clf.predict)になっていること、出力は回帰で統一されること(分類として扱いたい場合は出力がonehot形式になる必要がある)が挙げられます。
上記コードを実行すると以下のような結果が得られます。回帰問題となっているのでsentosaに対する確率ではなく、sentosaを指す0が出力値となっています。
予測結果はsetosaである(0.0)ということや、その要因はpetal lengthが1.4cmであることや、petal widthが0.2cmであることは変わっていませんね。

DeepExplainer
DeepExplainerはDeepLearningモデルに対してSHAP値を求めるためのモデルで、ドキュメントにはDeepLIFTを拡張したアルゴリズムを用いてSHAP値の条件付き確率を求めると記載されています。Kernelと同様に、データを渡して、そのデータを使ってSHAP値を計算するモデルを構築するようです。 下記ではVGGを用いて動作させています。このまま処理すると非常に時間がかかったので、下記のサイト様の例のようなスクリプトにする必要があるがありそうです。
https://orizuru.io/blog/machine-learning/shap/
import shap from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions #imageNetのデータを使うこととする。 image_X, image_y = shap.datasets.imagenet50() #SVCの学習済みモデルを用意する。 model = VGG16(include_top=True, weights='imagenet', input_tensor=None, input_shape=None) #SHAPのExplainerを用意する。DeepExplainerを使う。 explainer = shap.DeepExplainer(model, (preprocess_input(image_X))) #imageNetの20番目のデータを例にshap_valuesを求める。 #こう書くと時間がかかりすぎてしまう。 shap_values = explainer.shap_values(preprocess_input(image_X[[20]])) #予測に使ったデータに対して出力とその要因について可視化する。 shap.image_plot(shap_values, X[[20]])
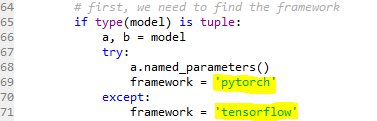
また、TreeExplainerの時と同様にどのようにモデルを識別しているかを追っていったところ、pytorchとtensorflowで分岐している個所があり、これらで作られたモデルなら動作するものと思います。逆に言うとChainer等のモデルでは使えないということですね。
summary_plot
summary_plotでは、特徴量がそれぞれのクラスに対してどの程度SHAP値を持っているかを可視化するプロットで、例えばirisのデータを対象にした例であれば以下のようなコードで実行できます。
#irisの全データを例にshap_valuesを求める。
shap_values = explainer.shap_values(iris_X)
#summary_plotを実行
shap.summary_plot(shap_values,
features=iris_X,
class_names=['setosa', 'versicolor', 'virginica'])
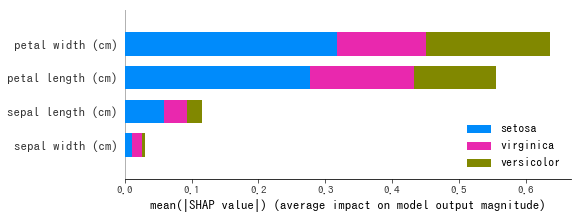
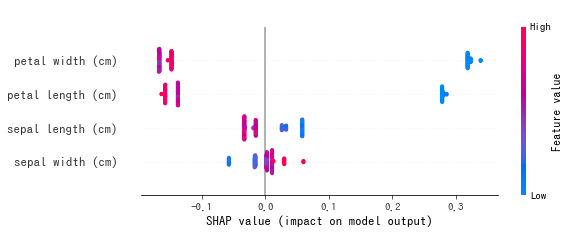
実行すると以下図が得られます。どのクラス を予測するにせよ、petal widthやpetal lengthが大きく影響しているということが読み取れます。
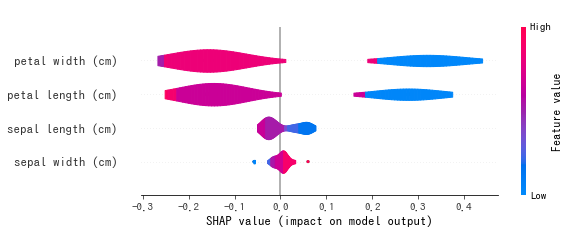
また、クラスを指定すれば散布図やバイオリンプロットでの出力も可能です。
shap.summary_plot(shap_values[0],
features=iris_X,
plot_type="dot", #又はviolin
)
実行すると以下のようなグラフを得ることができます。この図から、例えばsetosaの予測であれば、SHAP値が大きいのは petal_widthであり、色が青色なことから、値が小さいほどsetosaであると予測していることが読み取れます。
dependence_plot
dependence_plotでは、対象のクラスに対して、各特徴量の値とSHAP値の関係を可視化するもので、 例えばirisのsepal lengthデータを対象にした例であれば 以下のようなコードで実行できます。
#irisの全データを対象にshap_valuesを求める。
shap_values = explainer.shap_values(iris_X)
#dependence_plotを実行
shap.dependence_plot('sepal length (cm)',
shap_values[0],
features=iris_X
)
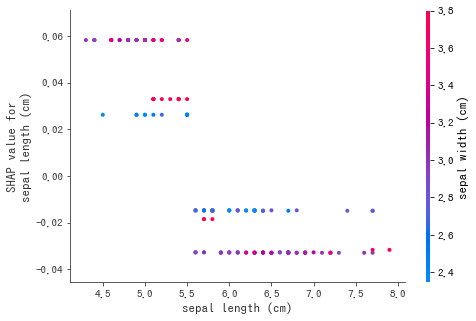
実行すると以下図が得られます。 sepal lengthが小さいほどSHAP値が上がり、大きいほど負の値が増していることから、 setosaに対する予測としては、
sepal length が大きいほど setosaではない可能性が高く、小さい
setosaである確率が高い関係であることが読み取れます。また、色情報として順番的に次の特徴量(sepal width)の値が示されています。
force_plot
force_plotでは、例で説明したように横棒グラフでSHAP値の関係を説明することができます。こんどはversicolorに対する予測の例で実行してみます。
#irisの最初のデータを例にshap_valuesを求める。
shap_values = explainer.shap_values(iris_X.loc[[0]])
#force_plotを実行。
shap.force_plot(explainer.expected_value[1],
shap_values[1],
iris_X.loc[[0]],
matplotlib=True,
)
petal widthやsepal lengthの値が影響していることが図示されました。
image_plot
image_plotは画像データを対象にshap_valuesを可視化するものです。以下のようなコードで実行できます。
shap.image_plot(shap_values, image_X[[0]])
画像のどこが効いているのかが非常に分かり易く示されています。実はこの画像、VGG16には「木」ではなく「車(street car)」と認識されてしまうのですが、右図の左下あたりに車っぽい形状の認識がされていることが確認でき、なぜ誤ったのかを読み取ることができますね。

まとめ
機械学習のモデルを問わずに用いることができ、予測に影響した特徴量の重要度を可視化できるライブラリであるshapの全メソッドを試して効果を検証してみました。shapはとても使いやすく効果も高いという印象です。今後、shapを求めるロジックの部分も勉強するつもりです。