はじめに
SageMakerはAWSで提供されているサービスの一つで、公式ページには以下の説明があります。
Amazon SageMaker は、ML 専用に構築された幅広い一連の機能をまとめて提供することにより、データサイエンティストとデベロッパーが高品質の機械学習 (ML) モデルを迅速に準備、構築、トレーニング、およびデプロイするのを支援します。
https://aws.amazon.com/jp/sagemaker/
いつも思うのですが、AWSが提供しているサービスの説明は技術者にはとても不親切というか、経営者向けの抽象的な説明を意識的に行っている節があります。SageMakerも同様で、このサービスがどのような用途で本当に使えるかどうか、知りたいなと思って試行しました。
試した機能
今回、私は以下の機能を試し、SageMakerとは概ね以下図のようなものなのだと理解しました。これらについて説明して行きます。
- ノートブックインスタンスを起動してアクセス
- sagemaker.estimator.Estimatorを使ってモデルを学習
- 学習済みモデルをエンドポイントとして登録して推論が出来ることを確認

ノートブックインスタンスを作成
まず、AWSのSageMakerのページにアクセスしてノートブックインスタンスを作成します。ノートブックインスタンスとは、Jupyterやその他必要ライブラリがインストールされたEC2ということだと私は理解しました。以下の公式チュートリアルも参考になります(読んでみるとS3の使用(アクセス権)について記載があり、S3が分からない人はまずこれから調べた方がいいです)。

作成すると、ステータスがPending状態になり、もう少し待つとデプロイが開始されます。起動すると[Jupyter を開くJupyterLab を開く]が表示されるので、そこに接続すればノートブック(Jupyter NotebookやJupyter Lab)が使えます。普段からJupyterを使い慣れている人は、ここからいつも通りに分析を進めていくことができます。
なお、このノートブックインスタンスは起動し続ける限り課金されるので、いらなくなったら停止することを忘れないようにしましょう。
sagemaker.estimator.Estimatorを使ってモデルを学習
sagemaker.estimator.Estimatorとは、SageMakerが提供しているライブラリで、初めて耳にした人はscikit-learnの各種学習アルゴリズムと似たようなものと考えるとまずはいいと思います。ただし、以下の点が異なります。
- このEstimatorによる計算は別のインスタンスで実行される
- このEstimatorはDockerイメージで構築されており、中身がどのようなアルゴリズムなのかは細かくは分かない。また、機械学習ライブラリとしての機能だけでなく、推論時はAPIとして使えるようなWebアプリケーションとしての機能も持っている
- このEstimatorで学習した学習済みモデルはエンドポイントとしてAPIのように使えるように登録できる
sagemaker.estimator.Estimatorを使う場合、普段のscikit-learnを使ったデータ分析とは根本的に異なるコードが必要になることを理解しなければいけません。以下、具体的にsagemaker.estimator.Estimatorを使って学習していくためのコードを張っていきます。
ノートブックインスタンスのJupyter上で以下を実施します。ここではデータとしてirisを使います。
# ライブラリのインポート import sagemaker import pandas as pd import numpy as np from sklearn.datasets import load_iris
リージョンと権限を確認します。適切でないとS3バケットにアクセスできません。
# リージョンと権限の確認
region = sagemaker.Session().boto_region_name
print("AWS Region: {}".format(region))
role = sagemaker.get_execution_role()
print("RoleArn: {}".format(role))
sagemaker.estimator.Estimatorでは、学習用データや学習済みモデルをS3に保存する仕様になっています。ここではモデルの保存先を指定しています。
# モデルを保存するバケットの設定
bucket = 'your-bucket'
prefix = 'tutorial'
s3_output_location='s3://{}/{}/{}'.format(bucket, prefix, 'xgboost_model')
xgboostの最新版を使います。printされるのはコンテナイメージのURLです。
# モデルアルゴリズムの設定
container = sagemaker.image_uris.retrieve("xgboost", region, "latest")
print(container)
ここではsagemaker.estimator.Estimatorを実行するマシンのスペックを定義します。つまり、学習だけリソースの大きなマシンを使うようなことが可能です。
# モデルの学習条件の設定
xgb_model=sagemaker.estimator.Estimator(
image_uri=container,
role=role,
instance_count=1,
instance_type='ml.m4.xlarge',
volume_size=5,
output_path=s3_output_location,
sagemaker_session=sagemaker.Session(),
rules=[sagemaker.debugger.Rule.sagemaker(sagemaker.debugger.rule_configs.create_xgboost_report())]
)
ここは学習用のハイパーパラメータの設定です。
# モデルのハイパーパラメータの設定
xgb_model.set_hyperparameters(
max_depth = 5,
eta = 0.2,
gamma = 4,
min_child_weight = 6,
subsample = 0.7,
objective = "multi:softmax",
num_class = 3,
num_round = 1000
)
sagemaker.estimator.EstimatorはS3の上に学習データや検証データを置く必要があるため、それらのデータを作成してS3にアップロードしています。
# 学習用データと検証用データの設定 bnk_data = load_iris() df_data = pd.DataFrame(np.concatenate([bnk_iris['target'].reshape(-1, 1), bnk_iris['data']], axis=1)) train_data, validation_data = np.split(df_data.sample(frac=1, random_state=1729), [int(0.7 * len(model_data))]) print(train_data.shape, validation_data.shape)
# 学習用データと検証用データのS3へのデータアップロード
train_data.to_csv('train.csv', index=False, header=False)
validation_data.to_csv('validation.csv', index=False, header=False)
validation_data.iloc[:, 1:].to_csv('test.csv', index=False, header=False)
sagemaker.Session().upload_data(bucket=bucket, path='train.csv', key_prefix='{}/{}'.format(prefix, 'data'))
sagemaker.Session().upload_data(bucket=bucket, path='validation.csv', key_prefix='{}/{}'.format(prefix, 'data'))
sagemaker.Session().upload_data(bucket=bucket, path='test.csv', key_prefix='{}/{}'.format(prefix, 'data'))
# 学習用データと検証用データの読み込み
train_input = sagemaker.session.TrainingInput(
"s3://{}/{}/{}".format(bucket, prefix, "data/train.csv"), content_type="csv"
)
validation_input = sagemaker.session.TrainingInput(
"s3://{}/{}/{}".format(bucket, prefix, "data/validation.csv"), content_type="csv"
)
fit(学習)を実行すると、新たなEC2インスタンスが立ち上がり、そこに勾配ブースティングのコンテナがダウンロード・デプロイされ、さらにS3からデータが取得され、学習が実行されます。
# モデルの学習
xgb_model.fit({"train": train_input, "validation": validation_input}, wait=True)
ここまで出来たら以下のコマンドで学習済みモデルをデプロイ(エンドポイントとして登録)することができます。デプロイ時にはマシンスペック等を設定することが可能です。このエンドポイントに推論用のデータをアップロードすると推論結果を受け取ることが出来るため、エンドポイント登録とはAPI化するようなイメージです。エンドポイント登録中は常に課金されてしまうことに注意しましょう。
# モデルのデプロイ
xgb_predictor = xgb_model.deploy(
initial_instance_count=1,
instance_type='ml.m4.xlarge',
serializer=sagemaker.serializers.CSVSerializer(),
)
推論実行時に必要になるのでエンドポイントの名称を確認しておきます。
# エンドポイント名の確認 xgb_predictor.endpoint_name
推論の動作確認
登録したエンドポイントにテスト用のデータをアップロードして推論結果を得ていきます。
# ライブラリのインポート import json import boto3 import pandas as pd from sklearn.metrics import confusion_matrix from sklearn.datasets import load_iris
エンドポイントにアクセスするためのクライアントを作成します。ここでは触れていませんが、APIGateway等の機能を作って本格的なAPIにすることも可能です。
# sagemakerにアクセスする
runtime = boto3.Session().client('sagemaker-runtime')
先ほど作成したエンドポイント名を指定します。
# 作成したエンドポイント名称 endpoint_name = 'xgboost-2021-06-23-15-11-33-222'
テストデータを読み出します。
# テストデータ読み込み
with open('test.csv', 'rb') as f:
payload = f.read()
print(payload)
エンドポイント名とテストデータをクライアントに設定してレスポンスを得ると、推論値が入っているので読み取ります。
# 指定したエンドポイントにデータを渡す
response = runtime.invoke_endpoint(EndpointName=endpoint_name,
ContentType='text/csv',
Body=payload)
# sagemakerからのレスポンスを受け取る
df_pred = pd.read_csv(response['Body'], header=None).T
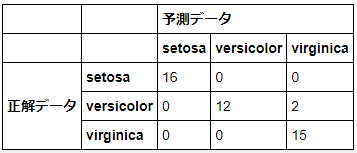
参考までに真値と混同行列で確認してみます。正しく動いていることが分かります。
# 真値読み込み
df_true = pd.read_csv('validation.csv', header=None, usecols=[0])
# 混同行列で精度確認
pd.DataFrame(
index=pd.MultiIndex.from_product([['正解データ'], load_iris()['target_names']]),
columns=pd.MultiIndex.from_product([['予測データ'], load_iris()['target_names']]),
data=confusion_matrix(df_true, df_pred, labels=[0, 1, 2])
)
まとめ
今回初めてSageMakerを真面目に試してみました。エンドポイントが課金され続けることがネックですが、確かに簡単にアプリケーション化できるように感じます。癖が多い印象ですが、機能は十分なため、商用利用が見込めるサービスを手短にリリースするような場合であれば使えるのかなと感じました。
参考サイト
今回の記事を作成するにあたって参考にさせていただいたURLを記載します。
- 全体を通じた公式チュートリアルその1。コードの量が多くてちょっとわかりにくい。
https://aws.amazon.com/jp/getting-started/hands-on/build-train-deploy-machine-learning-model-sagemaker/ - 全体を通じた公式チュートリアルその2。学習の部分だけならこちらの方が分かり易い。
https://docs.aws.amazon.com/sagemaker/latest/dg/ex1-train-model.html - SageMakerの学習や推論の基本的な考え方が分かる。
https://note.com/dd_techblog/n/nb48ddf0dd66b - 学習アルゴリズムのリポジトリの場所を探している。これを見てもどんなコンテナをどうすれば選べるかは分からない。
https://qiita.com/Roe/items/b47a8cec1e5f8c3c77ab - sagemakerライブラリでS3にアップロードする方法が書かれている。
https://stackoverflow.com/questions/56810011/unable-to-upload-a-file-from-sagemaker-notebook-to-s3 - xgboostでマルチオブジェクトを扱う方法が分かる。
https://sagemaker-examples.readthedocs.io/en/latest/introduction_to_amazon_algorithms/xgboost_mnist/xgboost_mnist.html - AWS LambdaとAPI Gatewayを用いて真面目にAPI化する方法が書かれている。https://recruit.cct-inc.co.jp/tecblog/machine-learning/how-to-sagemaker/