概要
自動微分を確認するための簡単なコードで、chainer/pytorch/tensorflowのコーディングの手間や計算時間を評価しました。手間はtensorflowがやや多い印象で、計算時間は条件によりpytorchとtensolfowのどちらかが1位になるという結果でした。
背景
2019年12月5日にchainerの開発が終了する発表がされました。
https://chainer.org/announcement/2019/12/05/released-v7-ja.html
これにより、このままchainerを使い続けることは出来なくなってしまったので、PFNが移行先として示しているpytorchか、もう1大勢力のtensorflowのどちらかにシフトする必要があります。
このどちらがよいのか、というのを判断するのはいろいろな基準があるかと思うのですが、私はこれらのライブラリをディープラーニングライブラリとしてよりも、自動微分の機能付きnumpyのように使いたいことが多いので、自動微分の使い勝手を基準に有効性を評価することにしました。
環境
本比較はGoogle Colabolatory上で実施しました。また検証時において各ライブラリのバージョンは以下の通りでした。
| chainer | 6.5.0 |
| pytorch | 1.4.0 |
| tensorflow | 1.15.0 |
また、それぞれのライブラリの自動微分は以下のサイトを参考にしました。
https://docs.chainer.org/en/stable/guides/variables.html
https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html
https://www.tensorflow.org/tutorials/customization/autodiff?hl=ja
検証スクリプト
以下2つの関数を題材にしました。1つ目はBがAの逆行列となるように誤差を算出する関数。もう1つはAに対して繰り返しBを乗算(行列積)を繰り返す関数です。なお、A及びBは以下のように乱数で取得します。
def get_A_B(size, seed=0): np.random.seed(seed) A = np.random.randn(size, size) B = np.random.randn(size, size)
chainer
関数1は10行、関数2は11行で記載できました。慣れていただけに惜しまれます。
#関数1 def try_chainer(size): A, B = get_A_B(size, seed=0) A_chainer = chainer.Variable(A) B_chainer = chainer.Variable(B) C_chainer = chainer.functions.matmul(A_chainer, B_chainer) E_chainer = chainer.functions.sum(chainer.functions.absolute(C_chainer - np.eye(C_chainer.shape[0]))) E_chainer.grad = np.ones_like(E_chainer.array) E_chainer.backward(retain_grad=True) print(A_chainer.grad)
#関数2
def try_chainer2(size, num):
A, B = get_A_B(size, seed=0)
A_chainer = chainer.Variable(A)
B_chainer = chainer.Variable(B)
C_chainer = chainer.functions.matmul(A_chainer, B_chainer)
for i in range(num):
C_chainer = chainer.functions.matmul(C_chainer, B_chainer)
C_chainer.grad = np.ones_like(C_chainer.array)
C_chainer.backward(retain_grad=True)
print(A_chainer.grad)
pytorch
想像以上にchainerと同じコードで記述できました。微分前にgradの値を設定する必要がなくなっています。関数1は9行、関数2は10行と一番少なく記述できました。chainerから見ると、tensor型とnumpyの直接の四則演算が出来なかったり、requires_gradの定義が必要、backward前にスカラーにする必要がある、などの違いがありました。
#関数1 def try_pytorch(size): A, B = get_A_B(size, seed=0) A_torch = torch.tensor(A, requires_grad=True) B_torch = torch.tensor(B) C_torch = torch.matmul(A_torch, B_torch) E_torch = torch.sum(torch.abs(C_torch - torch.eye(C_torch.shape[0]))) E_torch.backward() print(A_torch.grad)
#関数2
def try_pytorch2(size, num):
A, B = get_A_B(size, seed=0)
A_torch = torch.tensor(A, requires_grad=True)
B_torch = torch.tensor(B)
C_torch = torch.matmul(A_torch, B_torch)
for i in range(num):
C_torch = torch.matmul(C_torch, B_torch)
torch.sum(C_torch).backward()
print(A_torch.grad)
tensorflow
関数1が14行、関数2が15行と一番コーディングを要しました。計算グラフの記録が自動ではなくwith構文による定義が必要な点や、計算が自動では実行されず同様にwith構文で動作させなければいけない点が面倒に感じました。
#関数1
def try_tensorflow(size):
A, B = get_A_B(size, seed=0)
A_tensorflow = tensorflow.constant(A)
B_tensorflow = tensorflow.constant(B)
with tensorflow.GradientTape() as t:
t.watch(A_tensorflow)
C_tensorflow = tensorflow.matmul(A_tensorflow, B_tensorflow)
E_tensorflow = tensorflow.math.reduce_sum(tensorflow.abs(C_tensorflow - tensorflow.eye(C_tensorflow.shape[0].value, dtype=tensorflow.float64)))
dE_tensorflow_dA_tensorflow = t.gradient(E_tensorflow, A_tensorflow)
with tensorflow.Session() as sess:
dE_tensorflow_dA_tensorflow_result = sess.run([dE_tensorflow_dA_tensorflow])
print(dE_tensorflow_dA_tensorflow_result)
#関数2
def try_tensorflow2(size, num):
A, B = get_A_B(size, seed=0)
A_tensorflow = tensorflow.constant(A)
B_tensorflow = tensorflow.constant(B)
with tensorflow.GradientTape() as t:
t.watch(A_tensorflow)
C_tensorflow = tensorflow.matmul(A_tensorflow, B_tensorflow)
for i in range(num):
C_tensorflow = tensorflow.matmul(C_tensorflow, B_tensorflow)
dC_tensorflow_dA_tensorflow = t.gradient(C_tensorflow, A_tensorflow)
with tensorflow.Session() as sess:
dC_tensorflow_dA_tensorflow_result = sess.run([dC_tensorflow_dA_tensorflow])
print(dC_tensorflow_dA_tensorflow_result)
計算結果
%timeitを用いていくつかの条件で計算時間を計測・比較しました。なお、実際の結果はデータ作成の時間や順伝播の計算時間も含めていますがご容赦ください。
%timeit try_chainer(size) %timeit try_pytorch(size) %timeit try_tensorflow(size) %timeit try_chainer2(size, num) %timeit try_pytorch2(size, num) %timeit try_tensorflow2(size, num)
get_A_Bの計算時間
参考までにデータ取得の計算時間を記載します。データの増加に応じて時間が増えるという結果です。以降の結果では必要に応じてこの値を差し引いてください。
| size | 100 | 500 | 1000 | 3000 |
| 計算時間 | 945 us | 23.7 ms | 95.2 ms | 850 ms |
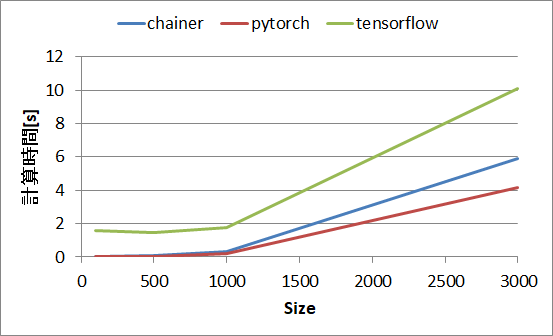
関数1の計算時間
sizeが大きくなると相対的に差が縮まっていますが、大きな計算時間の傾向はpytorch < chainer << tensorflowです。tensorflowが遅いことは以下等にも記載があります。
https://skymind.ai/japan/wiki/compare-dl4j-tensorflow-pytorch
https://arxiv.org/pdf/1608.07249v7.pdf
| size | 100 | 500 | 1000 | 3000 |
| chainer | 2.87 ms | 59.4 ms | 319 ms | 5.87 s |
| pytorch | 1.6 ms | 44.1 ms | 232 ms | 4.14 s |
| tensorflow | 1.57 s (1570 ms) | 1.48 s (1480 ms) | 1.79 s (1790 ms) | 10.1 s |
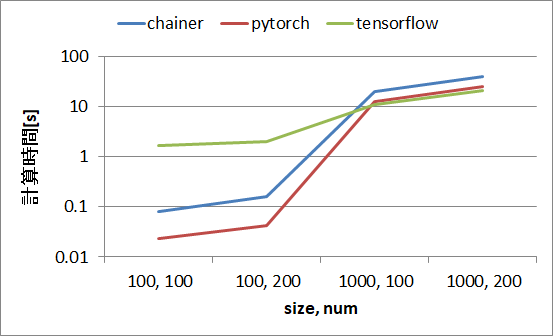
関数2の計算時間
sizeが100の場合はpytorch < chainer << tensorflowですが、sizeが1000になるとtensorflowが追い上げ、numが200のケースでは逆転しました。計算グラフが長くなる等で処理の負荷が高い場合にはtensorflowが強いということかもしれません。
| size | 100 | 100 | 1000 | 1000 |
| num | 100 | 200 | 100 | 200 |
| chainer | 81.5 ms | 162 ms | 20.4 s | 40.2 s |
| pytorch | 23.0 ms | 42.5 ms | 12.6 s | 25.1 s |
| tensorflow | 1.71 s (1710 ms) | 2.05 s (2050 ms) | 11.0 s | 20.8 s |
まとめ
自動微分を確認するための簡単なコードでchainerとpytorchとtensorflowを比較した結果、コーディングはtensorflowよりもchainerとpytorchの方が明らかに簡単と感じました。
計算時間は、処理が軽いうちはpytorch<chainer<<tensorflowですが、処理が重くなるとtensorflow<pytorch<chainerと逆転する傾向があることが分かりました。
ここから考えると、基本はpytorchで進めるが、処理が重い場合はtensorflowも検討するというところでしょうか。tensorflowのバージョンアップしたケースでの傾向や、ディープラーニングに用いることを考えると、GPUやTPUの場合の傾向も見ていく必要があるかもしれません。