概要
時系列データに対する有力な深層学習手法であるLSTM(Long Short Term Memory)は、非常に人気の高い手法ですが、具体的な処理の中身はよく分からずに使っているという人も多いと思います。本記事ではPreferred Networks社が提供する深層学習ツールである chainerのLSTMの処理内容を追いかけ、LSTMがどういった処理をしているのかを以下のポイントで整理した結果を解説していきます。
- 全体的な動きについて
- メモリセル、 input gate, output gate, forget gateとは何なのか
- 学習されるパラメータと値へのアクセス方法について
全体的な動きについて
以下に、Chainerのlstmクラス(具体的にはchainer.link.lstm)の処理を追いかけて作成したフローチャートを示します。xが入力、y(=h)が出力であり、下から上に向かって処理が進んでいく図になっています。なお、図内において文字で表記している項目(x(t)等)は列ベクトル、四角で囲っている項目(sigmoid等)はファンクション、●項目(sum等)は演算を示しています。またマゼンダの色はパラメータ要素がないこと、緑文字は過去の値を保持して再利用することを示しています。以下手順ごとに説明していきます。
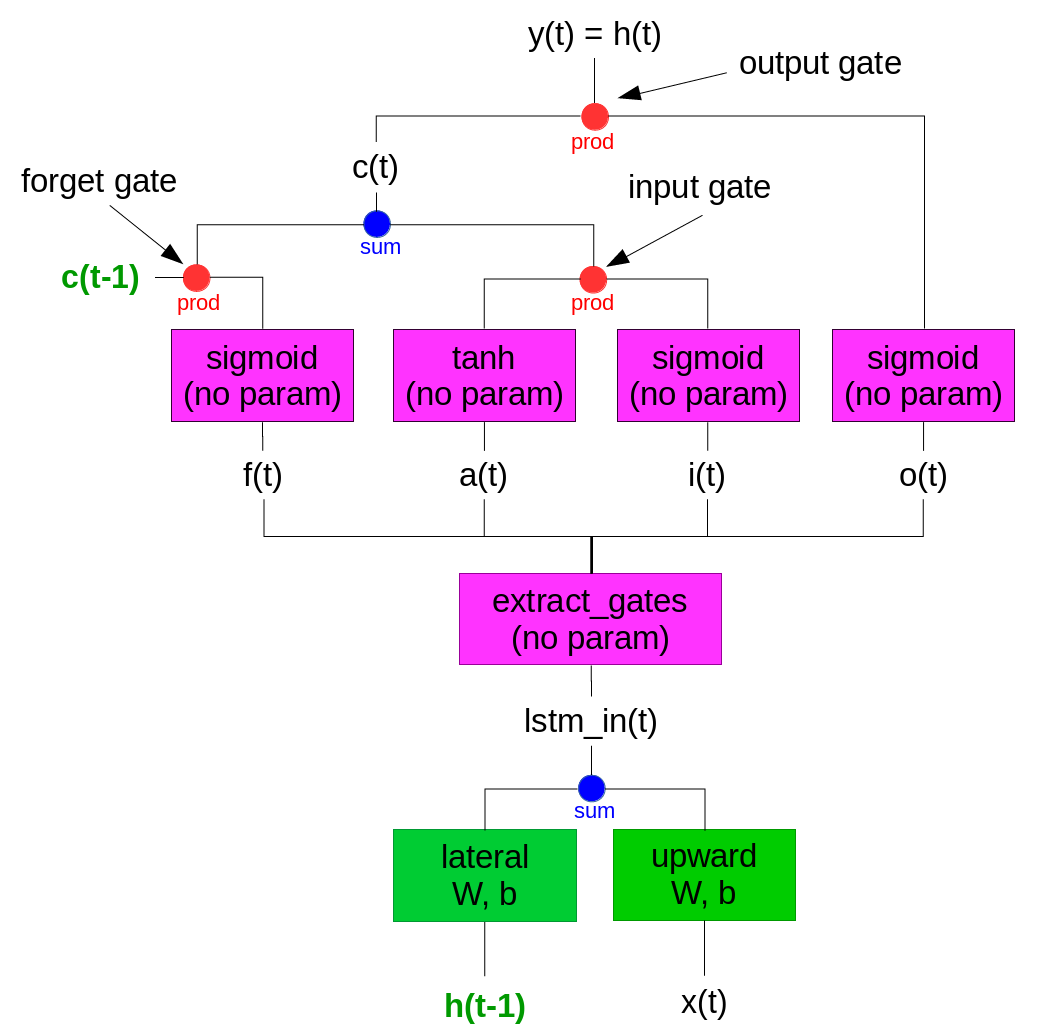
x(t)とh(t-1)からlstm_in(t)を計算するまで
x(t)はlstmクラスへの入力であり、説明変数又は前段のNN(ニューラルネットワーク)の出力に相当するものです。Chainerでは行数1、列数が入力データの列数(n_input)と等しい列ベクトルとして扱われます(厳密にはバッチ学習する際はバッチが行要素として扱われるのですが、説明を簡略化するために以降は総てバッチ数1として扱います)。h(t-1)は、前回計算の出力値であり、前回時刻における目的変数又は後段のNNの入力に相当するものです。Chainerでは行数1、列数が出力データの列数(n_output)と等しい列ベクトルとして扱われます。
h(t-1)にはlateralオブジェクトのWとbを用いた線形変換を、x(t)にはupwardオブジェクトのWとbを用いた線形変換を適用し、共にサイズを1×(4×n_output)としてから和を計算するとlstm_in(t)となります。
| 変数名 | 説明 | 形状 |
| x(t) | lstmへの入力 | 1×n_input |
| h(t-1) | lstmの前回出力 | 1×n_output |
| lstm_in(t) | h(t-1)を含めたlstmへの入力 | 1×(4×n_output) |
lstm_in(t)からa(t), i(t), o(t), f(t)を計算するまで
lstm_in(t)にextract_gatesを適用してa(t), i(t), o(t), f(t)を計算します。この処理は以下図に示すように、データの並び替えをして4つに分離しているだけのようです。

| 変数名 | 説明 | 形状 |
| a(t) | lstmへの入力のうちcell_inputとして使われる要素 | 1×n_output |
| i(t) | lstmへの入力のうちinput_gateとして使われる要素 | 1×n_output |
| o(t) | lstmへの入力のうちoutput_gateとして使われる要素 | 1×n_output |
| g(t) | lstmへの入力のうちforget_gateとして使われる要素 | 1×n_output |
c(t-1), a(t), i(t), f(t)からc(t)を計算するまで
c(t-1)は前回計算の結果のメモリセルであり、Chainerでは行数1、列数が出力データの列数(n_output)と等しい列ベクトルとして扱われます。sigmoidはシグモイド関数で計算することを示し、各要素ごとに0~1の値に変換されます。tanhはtanのハイパボリック関数で計算することを示しており、同様に各要素ごとに-1〜1の値に変換されます。これらの値を使ってcの更新を実施します。
c(t) = c(t-1) × sigmoid(f(t)) + tanh(a(t)) * sigmoid(i(t))
| 変数名 | 説明 | 形状 |
| c(t-1) | 前回計算の結果のメモリセル | 1×n_output |
| c(t) | 更新したメモリセル | 1×n_output |
c(t), o(t)からy(t)(=h(t))を計算するまで
更新したc(t)にシグモイド処理をしたo(t)を積算することで出力y(t)を計算します。以上がChainerのlstmでの動作の流れになります。(forwardについてのみ。backwardは逆にたどるだけなので省略しました。)
y(t) = c(t) * sigmoid(o(t))
h(t) = y(t)
| 変数名 | 説明 | 形状 |
| y(t) | lstmの出力 | 1×n_output |
| h(t) | y(t)と同値 | 1×n_output |
メモリセル、 input gate, output gate, forget gateとは何なのか
LSTMについてしばしば???となってしまう上記4要素については、上記の流れから以下のように理解すればよいと思います。
メモリセル・・・実態は1×n_outputの実数値の配列。この値にoutput gateの値を積算したものが出力になる。LSTMが動作するたびに上書きされる。アルゴリズム的にはこの値が時系列の概念を表していることが望まれると考えられる。
input gate・・・入力データを通常のNNと同様に全結合したあと、同様に1コマ前の出力を全結合した値に加えたlstmの入力a(t)について、その値の何%をメモリに入力するかを指定する。アルゴリズム的にはnoisyなデータは低く、有効性の高い情報は高くなることが望まれると考えられる。
output gate・・・メモリセルから何%の値を出力するかを指定する。アルゴリズム的には時系列の状態に応じて適切な値が出力されることが望まれると考えられる。
forget gate・・・メモリセルから何%の値を次に残すかを指定する。アルゴリズム的には長期保存すべきデータは長く残し、短期保存で良いデータは早く忘れることが望まれると考えられる。
LSTMのメモリセルと呼ばれる概念は実際には小さな配列であり、また構成の中にCNNのプーリングのような制約的な要素もないことから、実態としては理想的な学習はなかなか出来ていないことが多いのではと考えられます(LSTMの学習の中身について考察された論文もあまり見ないです)。とは言え、これらが望ましい動きをしているかどうかを検証することがLSTMの精度を向上させる鍵になりそうですね。
学習されるパラメータと値へのアクセス方法について
LSTMで学習される要素は、lateralとupwardに含まれるWとbだけのようです。このことが分かると、LSTMに対する不明感は幾分和らぐのではないでしょうか。(一応、普通の全結合層はupwardのa(t)だけですから、入出力の層が同じ数だとすれば、lateralと合わせて、パラメータ数は8倍になってはいますが。)
なお、Chainer(2.0.2)では、以下のコマンドで各要素にアクセスできます。モデル内のLSTMの要素を仮にmodel.l1とします。
| 変数名 | コマンド |
| メモリセル | model.l1.c |
| 前回出力 | model.l1.h |
| lateral | model.l1.lateral |
| lateralのW | model.l1.lateral.W |
| lateralのb | model.l1.lateral.b |
| upward | model.l1.upward |
| upwardのW | model.l1.upward.W |
| upwardのb | model.l1.upward.b |
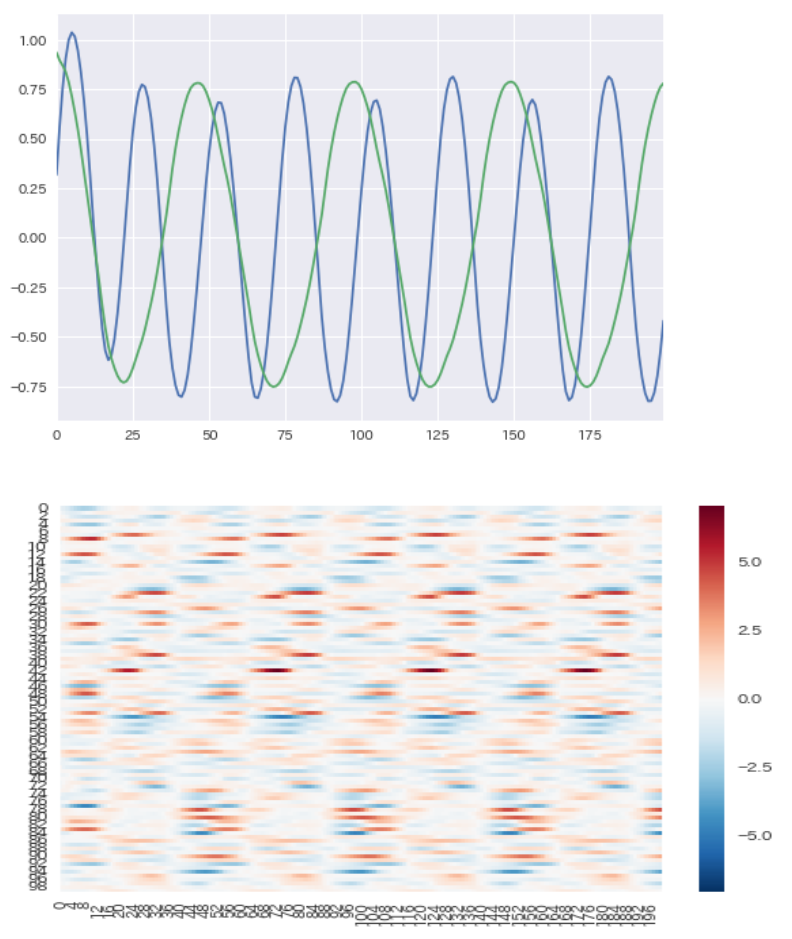
参考までに前回記事で実施したsin波とcos波を学習したモデルでメモリセル(100次元)を可視化すると以下のようになりました。周期性の傾向は出ており、こういった切り口からの分析は確かに面白いかもしれません。
まとめ
本記事では、LSTMの動作を、Chainerのライブラリの処理を追うことで整理し、解説しました。LSTMではメモリセルや各種ゲート等の分かりにくい表現が使われますが、小さな配列をメモリとみなして過去情報を残しておく、学習されるのは2種類の全結合層のみ、ということが分かればそれほど難しいものではないと言えます。今後LSTMを活用しながら有効性を検証していきたいです。