概要
過去記事でPandasのデータフレームを→Sklearnのデータセットに変換する関数(pan2sk)を作っていたので、反対側のSklearnのデータセットをPandasのデータフレームに変換する関数(sk2pan)も作ってみました。要件定義は以下です。
- 全体を1つのデータフレームとする
- カラム名は説明変数はfeature_names, 目的変数は引数で与えるものとする。(デフォルトはTarget)
- target_namesがある場合、値を置換する
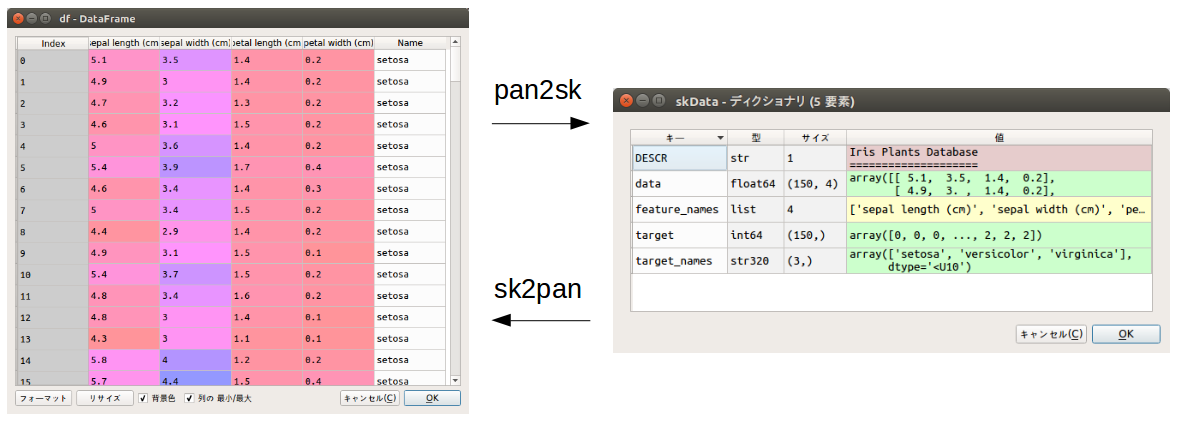
GitHubにて、ソースコードを公開しています。また、ページの末尾に全ソースコードを載せています。
使い方
sk2panにsklearnのデータセットと目的変数のカラム名を渡すと、pandasのデータフレームに変換されます。
skData = datasets.load_iris()
df = sk2pan(skData, target='Name')
dfは以下のようになっており、目的の形式になっています。
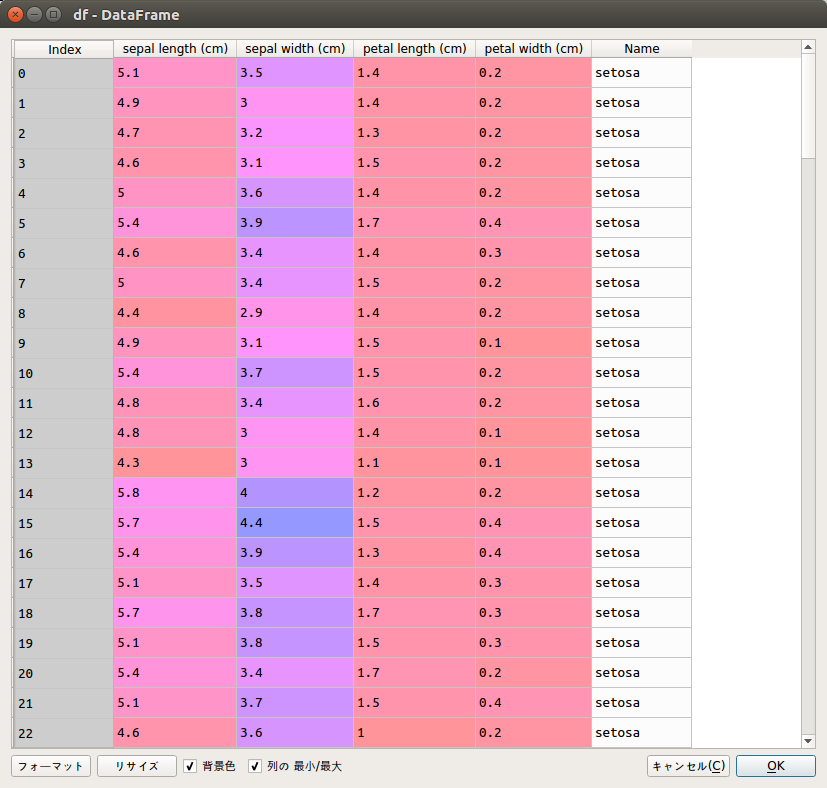
是非活用してみてください。
全ソースコード
import pandas as pd
import numpy as np
from sklearn import datasets
import sklearn.preprocessing as sp
def pan2sk(df, target, name="Data"):
"""
<概要>
pandasのデータフレームをscikit-learnの入力データに変換する関数
<引数>
df:データフレーム
target:目的変数のカラム名
<出力>
Bunch:scikit-learn形式に変換したデータ
"""
#説明変数のデータ列と目的変数のデータ列に分ける
expdata = df[df.columns[df.columns!=target]]
objdata = df[target].copy()
#説明変数の各データについて変換
for column in expdata.columns:
#数値データはそのまま
if (expdata[column].dtypes == int) or (expdata[column].dtypes == float):
pass
#カテゴリデータはバイナリ化
elif expdata[column].dtypes == object:
temp = pd.DataFrame(index=expdata[column].index, columns=column + " = " + expdata[column].unique()
, data=sp.label_binarize(expdata[column], expdata[column].unique()))
expdata = pd.concat([expdata, temp], axis=1)
del expdata[column]
#それ以外のデータ(時系列等)は除外
else:
del expdata[column]
#説明変数のデータとカラム名を分けておく
data=np.array(expdata)
feature_names=np.array(expdata.columns)
#目的変数のデータをシリアル化する
#数値データはそのまま登録
if (objdata.dtypes == int) or (objdata.dtypes == float):
targetData = np.array(objdata)
target_names = []
#カテゴリデータはシリアル化して登録
if objdata.dtypes == object:
le = sp.LabelEncoder()
le.fit(objdata.unique())
targetData = le.transform(objdata)
target_names = objdata.unique()
#データセットの名称を用意
DESCR = name
#オブジェクト作成
skData = datasets.base.Bunch(DESCR=DESCR, data=data, feature_names=feature_names, target=targetData, target_names=target_names)
return skData
def sk2pan(skData, target="Target"):
expdata = pd.DataFrame(skData.data, columns=skData.feature_names)
objdata = pd.DataFrame(skData.target, columns=[target])
try:
objdict = dict(zip(np.arange(skData.target_names.shape[0]), skData.target_names))
objdata = objdata[target].map(objdict)
except:
pass
return pd.concat([expdata, objdata], axis=1)
if __name__ == "__main__":
df = pd.read_csv("iris.csv")
skData = pan2sk(df, target='Name', name='iris')
skData = datasets.load_iris()
df = sk2pan(skData, target='Name')