概要
前回記事で検討した以下の要件定義を元にスクリプトを作成しました。
GitHubにて、ソースコードを公開しています。また、ページの末尾に全ソースコードを載せています。
- 説明変数のデータ列と目的変数のデータ列に分ける
- 説明変数のデータを下記の通り変換する
- 数値データはそのまま
- カテゴリデータはバイナリ化
- それ以外のデータ(時系列等)は除外
- 説明変数のデータとカラム名を分けてオブジェクトのメンバに割り付ける
- 目的変数のデータをシリアル化する
- 目的変数の値と名称を分けてオブジェクトのメンバに割り付ける
- データセットの名称をオブジェクトのメンバに割り付ける
使い方
pan2skにpandasのデータフレームと目的変数のカラム名、データフレーム名(なくても可)を渡すと、sklearnのデータ形式を返してくれます。
df = pd.read_csv("iris.csv", index_col=0)
skData = pan2sk(df, target='Name', name='iris')
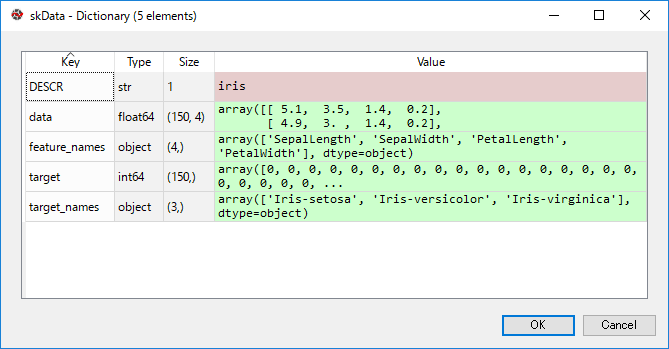
skDataは以下のようになっており、目的の形式になっています。
コーディング
説明も兼ねて部分部分に分けて解説していきます。全体のソースコードは末尾を参照ください。
必要モジュールのインポート
本機能を実装するにあたり必要なモジュールをインポートします。
import pandas as pd import numpy as np from sklearn import datasets import sklearn.preprocessing as sp
datasetsはscikit-learnのデータセットの構造を使うためにインポート、preprocessingは同前処理機能を使うためにインポートしています。preprocessingについては下記記事に詳しく書きましたので参考にしてください。pandas、numpyはお馴染みのモジュールのため、説明は省略します。
関数名と引数
関数名はpan2sk(パン○好き)としました。引数はデータフレームと目的変数、そしてデータ名です。データ名に関してはデフォルトでDataという名称を与えています。”””で挟まれた部分はhelp扱いとなり、help(pan2sk)と打つと表示される内容になります。
def pan2sk(df, target, name="Data"):
"""
<概要>
pandasのデータフレームをscikit-learnの入力データに変換する関数
<引数>
df:データフレーム
target:目的変数のカラム名
<出力>
Bunch:scikit-learn形式に変換したデータ
"""
説明変数のデータ列と目的変数のデータ列の分離
dfからtargetに一致しないデータを説明変数(expdata)、一致するデータを目的変数(objdata)としています。
#説明変数のデータ列と目的変数のデータ列に分ける
expdata = df[df.columns[df.columns!=target]]
objdata = df[target].copy()
説明変数のデータ変換
数値データはそのまま、カテゴリデータはバイナリ化、それ以外のデータは除外します。カテゴリデータの処理は①tempにバイナリ後のデータを格納、②expdataに結合、③もともとの列を削除という手順で実施しています。面倒そうな処理ですが、実はunique()とlabel_binarize()を使うことで簡単に実現します。
for column in expdata.columns:
#数値データはそのまま
if (expdata[column].dtypes == int) or (expdata[column].dtypes == float):
pass
#カテゴリデータはバイナリ化
elif expdata[column].dtypes == object:
temp = pd.DataFrame(index=expdata[column].index, columns=column + " = " + expdata[column].unique()
, data=sp.label_binarize(expdata[column], expdata[column].unique()))
expdata = pd.concat([expdata, temp], axis=1)
del expdata[column]
#それ以外のデータ(時系列等)は除外
else:
del expdata[column]
#説明変数のデータとカラム名を分けておく
data=np.array(expdata)
feature_names=np.array(expdata.columns)
目的変数のデータ変換
数値データはそのまま、カテゴリデータはシリアル化します。これも同様に、unique()とLabelEncoder()を使うことで簡単に実現します。
#目的変数のデータをシリアル化する
#数値データはそのまま登録
if (objdata.dtypes == int) or (objdata.dtypes == float):
targetData = np.array(objdata)
target_names = []
#カテゴリデータはシリアル化して登録
if objdata.dtypes == object:
le = sp.LabelEncoder()
le.fit(objdata.unique())
targetData = le.transform(objdata)
target_names = objdata.unique()
オブジェクト作成
最後にオブジェクトに割り当てれば完成です。
#データセットの名称を用意
DESCR = name
#オブジェクト作成
skData = datasets.base.Bunch(DESCR=DESCR, data=data, feature_names=feature_names, target=targetData, target_names=target_names)
return skData
まとめ
「pandasで読み込んだデータをそのままscikit-learnの分析ライブラリに投入」するためのライブラリ[pan2sk]を作ってみました。
今後は細かいエラー処理や並列計算、正規化や教師なし学習への対応等を進めていきたいです。
全ソースコード
import pandas as pd
import numpy as np
from sklearn import datasets
import sklearn.preprocessing as sp
def pan2sk(df, target, name="Data"):
"""
<概要>
pandasのデータフレームをscikit-learnの入力データに変換する関数
<引数>
df:データフレーム
target:目的変数のカラム名
<出力>
Bunch:scikit-learn形式に変換したデータ
"""
#説明変数のデータ列と目的変数のデータ列に分ける
expdata = df[df.columns[df.columns!=target]]
objdata = df[target].copy()
#説明変数の各データについて変換
for column in expdata.columns:
#数値データはそのまま
if (expdata[column].dtypes == int) or (expdata[column].dtypes == float):
pass
#カテゴリデータはバイナリ化
elif expdata[column].dtypes == object:
temp = pd.DataFrame(index=expdata[column].index, columns=column + " = " + expdata[column].unique()
, data=sp.label_binarize(expdata[column], expdata[column].unique()))
expdata = pd.concat([expdata, temp], axis=1)
del expdata[column]
#それ以外のデータ(時系列等)は除外
else:
del expdata[column]
#説明変数のデータとカラム名を分けておく
data=np.array(expdata)
feature_names=np.array(expdata.columns)
#目的変数のデータをシリアル化する
#数値データはそのまま登録
if (objdata.dtypes == int) or (objdata.dtypes == float):
targetData = np.array(objdata)
target_names = []
#カテゴリデータはシリアル化して登録
if objdata.dtypes == object:
le = sp.LabelEncoder()
le.fit(objdata.unique())
targetData = le.transform(objdata)
target_names = objdata.unique()
#データセットの名称を用意
DESCR = name
#オブジェクト作成
skData = datasets.base.Bunch(DESCR=DESCR, data=data, feature_names=feature_names, target=targetData, target_names=target_names)
return skData
if __name__ == "__main__":
df = pd.read_csv("iris.csv", index_col=0)
skData = pan2sk(df, target='Name', name='iris')