概要
Preferred Networks社が提供する深層学習ツールである chainerを使ってニューラルネットワークを学習する手順を整理しました。大きな流れは以下です。
- Chainerが使える形にデータを整形する
- 学習するニューラルネットワークのモデルを定義する
- その他の学習条件・パラメータをセットし、trainerを構築する
- 学習を実行し、学習結果を確認する
なお、chainer自体は以下のコマンドで簡単にインストールできます。
pip install chainer
また、以下のモジュールがimportされているものとします。
import pandas as pd import numpy as np import sklearn.preprocessing as sp import chainer from chainer import cuda, Function, gradient_check, report, training, utils, Variable from chainer import datasets, iterators, optimizers, serializers from chainer import Link, Chain, ChainList import chainer.functions as F import chainer.links as L from chainer.training import extensions from chainer.functions.loss.mean_squared_error import mean_squared_error from chainer.datasets import tuple_dataset
Chainerが使える形にデータを整形する
具体的には以下の状態を満たしていることを指します。
- データが全てNumpyのArray型になっている
- データが全て数値(int又はfloat)型になっている
- データが全て32bit型になっている
- データが学習データと検証データに分かれている
- データが説明変数と目的変数に分かれている
NumpyのArray型にする
元データがlist型やpandasのDataFrame型になっている場合、np.arrayのコマンドを使ってarray型に変更しましょう。
data = np.array(hoge)
全て数値(int又はfloat)型にする
文字列データが混じっている場合は数値にエンコードしておきましょう。以下ではDataFrameの1列目が文字列データだったとして、数値データにエンコードするスクリプトを示しています。
le = sp.LabelEncoder() le.fit(df[df.columns[0]].unique()) df[df.columns[0]] = le.transform(df[df.columns[0]])
scikit-learnのpreprocessingについては以下記事も参考にしてみてください。
数値データを32bit型にする
chainerは64bitのデータ型を扱ってくれません。astypeを使って32bit型に置き換えましょう。
#float型の場合 data = data.astype(np.float32) #int型の場合 data = data.astype(np.int32)
学習データと検証データに分ける
機械学習をする上では基本的な話ですが、学習データと検証データに分けておきましょう。ランダムに分割したかったら、numpy.random.choice等を使えばいいと思います。
説明変数と目的変数に分ける
説明変数の集合(data)と目的変数(target)に分けておきましょう。所謂Scikit-learnのBunch型にしておくと尚いいと思います。DataFrame型をBunch型にする方法については以下記事を参考にしてください。
学習するニューラルネットワークのモデルを定義する
Chainを継承したクラスを作り、initで構造を、callで計算内容を定義します。以下に例を示します。
class MyChain(Chain):
def __init__(self):
super(MyChain, self).__init__(
l1=L.Linear(4, 5),
l2=L.Linear(5, 5),
l3=L.Linear(5, 3)
)
def __call__(self, x):
h1 = F.sigmoid(self.l1(x))
h2 = F.sigmoid(self.l2(h1))
o = self.l3(h2)
return o
その他の学習条件・パラメータをセットし、trainerを構築する
具体的には以下を設定します。
- データオブジェクトの作成と抽出オプションの設定
- モデルと最適化関数の設定
- 学習回数の設定とtrainer構築
trainerの構成は以下のイメージです。
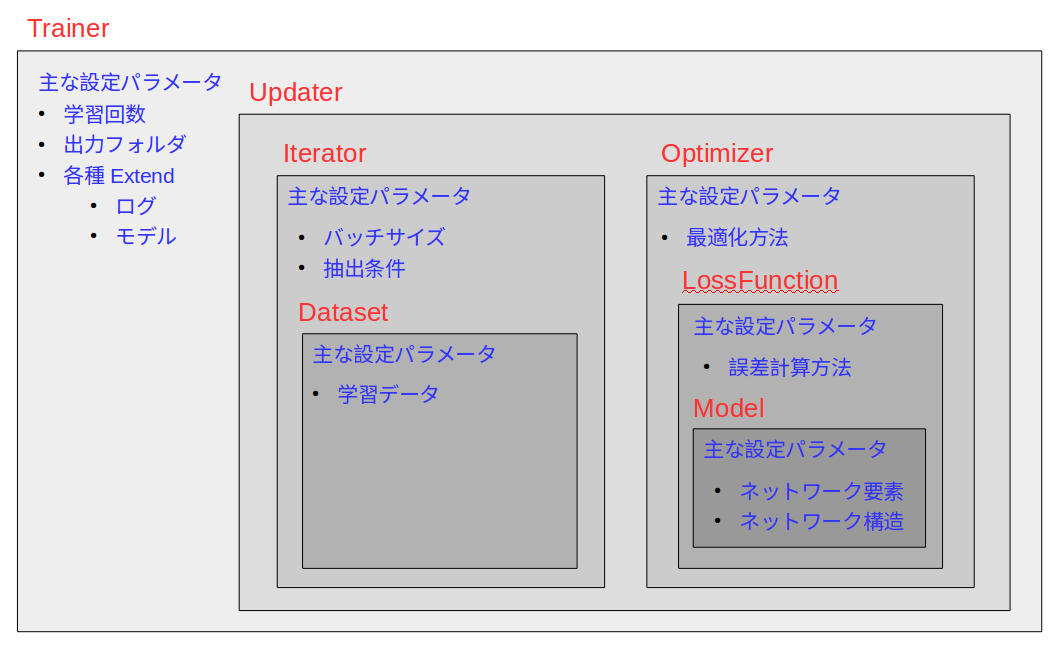
データオブジェクトの作成と抽出オプションの設定
まずtuple_datasetを使ってchainerで使えるオブジェクトを作ります。
train = tuple_dataset.TupleDataset(data, target)
その後抽出オプションを指定してイテレータ型にします。こうすることで、trainerをrunしたときに自動的にランダムにデータを抽出してバッチ学習がすることができます。(これは便利!)
train = iterators.SerialIterator(train, batch_size=batch, shuffle=True, repeat=True)
モデルと最適化関数の設定
まず定義したモデルを使う宣言をします。説明変数がクラス型の時はClassifierを指定すると適切に処理されます。
model = L.Classifier(MyChain())
次に最適化関数を指定します。ここではSGDを指定しています。こうすることでrunの度に自動で最適化計算が走ります。さらにこれにモデルを割り当てます。
optimizer = optimizers.SGD() optimizer.setup(model)
そして、学習データを割り当てます。
updater = training.StandardUpdater(train_iter, optimizer)
学習回数の設定とtrainer構築
最後に学習回数(epoch)を指定すればtrainer構築完了です。
trainer = training.Trainer(updater, (epoch, 'epoch'), out='result')
学習を実行し、学習結果を確認する
以下を実行することで自動的に指定回数の学習が行われます。
trainer.run()
またこのとき、extendを指定しておくと、モデルの保存や精度確認等が行えます。
#精度確認
trainer.extend(extensions.Evaluator(test_iter, model))
#レポート出力
trainer.extend(extensions.LogReport())
#レポート内容
trainer.extend(extensions.PrintReport(['epoch', 'main/accuracy', 'validation/main/accuracy']))
#プログレスバー出力
trainer.extend(extensions.ProgressBar())
#モデルの保存
trainer.extend(extensions.snapshot(trigger=(1, 'epoch'), filename='snapshot_iter_{0:04d}', mode='a'))
Irisデータで実証
irisのデータを使って検証してみました。実行するとコンソール上に以下のような画面が出力されるはずです。今回の例では学習データと検証データに同じデータを指定しているという条件ですが、50回の学習で精度33%→90%程度まで上昇しており、確かにニューラルネットワークが学習されていることが確認できました。

import glob
import pickle
import pandas as pd
import numpy as np
import sklearn.preprocessing as sp
import random
import chainer
from chainer import cuda, Function, gradient_check, report, training, utils, Variable
from chainer import datasets, iterators, optimizers, serializers
from chainer import Link, Chain, ChainList
import chainer.functions as F
import chainer.links as L
from chainer.training import extensions
from chainer.functions.loss.mean_squared_error import mean_squared_error
from chainer.datasets import tuple_dataset
def set_random_seed(seed):
# set Python random seed
random.seed(seed)
# set NumPy random seed
np.random.seed(seed)
class MyChain(Chain):
def __init__(self):
super(MyChain, self).__init__(
l1=L.Linear(4, 5),
l2=L.Linear(5, 5),
l3=L.Linear(5, 3)
)
def __call__(self, x):
h1 = F.sigmoid(self.l1(x))
h2 = F.sigmoid(self.l2(h1))
o = self.l3(h2)
return o
if __name__ == "__main__":
epoch = 50
batch = 1
df = pd.read_csv("iris.csv")
data = np.array(df.iloc[:, :-1].astype(np.float32))
# target = sp.label_binarize(df[df.columns[4]], classes=df[df.columns[4]].unique()).astype('float32')
le = sp.LabelEncoder()
tmp = df[df.columns[4]].unique()
tmp.sort()
le.fit(tmp)
target = le.transform(df[df.columns[4]]).astype('int32')
set_random_seed(0)
train = tuple_dataset.TupleDataset(data, target)
test = tuple_dataset.TupleDataset(data, target)
train_iter = iterators.SerialIterator(train, batch_size=batch, shuffle=True)
test_iter = iterators.SerialIterator(test, batch_size=batch, repeat=False, shuffle=False)
model = L.Classifier(MyChain()) #, lossfun=mean_squared_error
optimizer = optimizers.SGD()
optimizer.setup(model)
updater = training.StandardUpdater(train_iter, optimizer)
trainer = training.Trainer(updater, (epoch, 'epoch'), out='result')
trainer.extend(extensions.Evaluator(test_iter, model))
trainer.extend(extensions.LogReport())
trainer.extend(extensions.PrintReport(['epoch', 'main/accuracy', 'validation/main/accuracy']))
trainer.extend(extensions.ProgressBar())
trainer.extend(extensions.snapshot(trigger=(1, 'epoch')))
trainer.run()
ソースコードから、MyChainの部分をより細かく設定するだけでディープラーニングにできることはご理解いただけると思います。実に100行足らずであり、内容もとても合理的と思いますので、私的にはchainerはとても使い易いソフトと考えています。