概要
Pythonでデータ分析する際に必須のpandasとscikit-learnは、現状入力IFが整っておらず、「pandasで読み込んだデータをそのままscikit-learnの分析ライブラリに投入」ということができません。これは分析を始めようとした際に厄介なポイントなので、対策を考えて汎用コードを書いてしまおう、というのが今回の記事です。
データ構造の確認
まずはpandasとscikit-learnのデータ構造を確認してみましょう。
Pandasのデータ構造
pandasを使ってirisのデータを読み込んでみます。
import pandas as pd
df = pd.read_csv("iris.csv", index_col=0)
spyderのVariable explorerで確認するとこんな感じ。
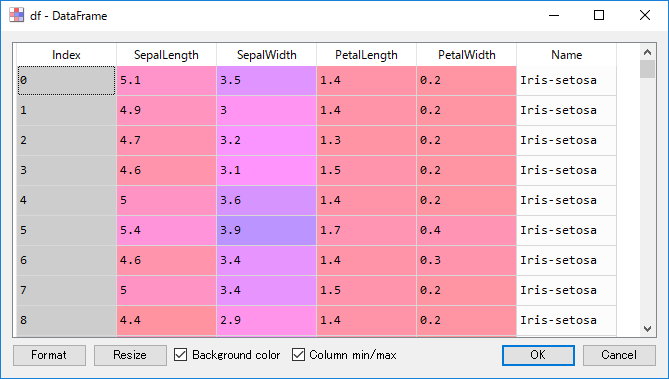
ざっくり以下の特徴があります。
- 1つのテーブルで完結
- Indexとcolumnを持つ
- 数値データと文字データが混在
Scikit-learnのデータ構造
sklearnを使ってirisのデータサンプルを読み込んでみます。
from sklearn import datasets sample = datasets.load_iris()
同様にspyderのVariable explorerで確認するとこんな感じ。
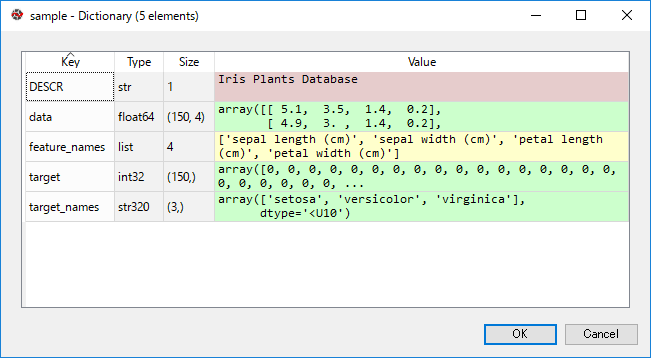
pandasのデータフレームとはかなり形状が違うことが分かります。
- 5つのメンバを持つ(データ名、説明変数のデータ、 説明変数のカラム名、目的変数のデータ、目的変数の名称
- 各データはNumpy配列
- 各データは数値データのみ
データ変換要件
PandasからScikit-learnのデータに構造を変換するためには、以下の作業が必要なことが分かりました。
- 説明変数のデータ列と目的変数のデータ列に分ける
- 説明変数のデータを下記の通り変換する
- 数値データはそのまま
- カテゴリデータはバイナリ化
- それ以外のデータ(時系列等)は除外
- 説明変数のデータとカラム名を分けてオブジェクトのメンバに割り付ける
- 目的変数のデータをシリアル化する
- 目的変数の値と名称を分けてオブジェクトのメンバに割り付ける
- データセットの名称をオブジェクトのメンバに割り付ける
次の記事でコーディングを進めていきます。
