はじめに
その2では、「loto6に当たりやすい目はあるのか?」について以下の手順で分析・解析していきます。
- 今までに出た目は偏りがあるか?
- 偏りは統計的に妥当か?
データの入手方法や環境の設定方法に関してはその1を参照してください。
今までに出た目は偏りがあるか?
まず、ロト6の出目を確認し、どれだけ偏りがあるのかを確認しましょう。
出目の確認
早速、出目の偏りを確認していきます。
#Pandasを用いてデータを読み込み、データフレームに格納します。
import pandas as pd
df = pd.read_csv("loto6.csv", encoding="cp932", parse_dates=[1])
#抽選番号に係るデータだけを使う
df = df.iloc[:, 3:10]
#データ確認
df.head()
ここから、meltとpivot_tableを用いて、数値ごとの出現回数が分かるように整形します。
#まずはpandasのmeltを用いて数値を1列の項目に変換
df = pd.melt(df)
#データ確認
df.head()
#次にpivot-tableを用いて数値ごとの抽選回数を算出
df = pd.pivot_table(df, index='value', aggfunc='count')
df.columns = ['frequency']
#データ確認
df.head()
回数が分かったので引き続き可視化してみましょう。
#棒グラフで可視化
%matplotlib inline
df.plot.bar(figsize=(8, 6))
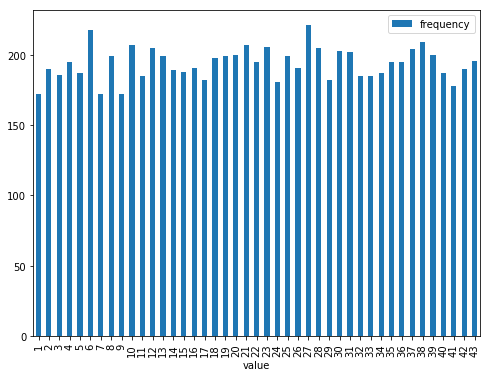
見えにくいので並び替えを行い、加えてもう少しy軸の範囲を絞ります。
df.sort_values('frequency', ascending=False).plot.bar(ylim=[150, 230], figsize=(8, 6))
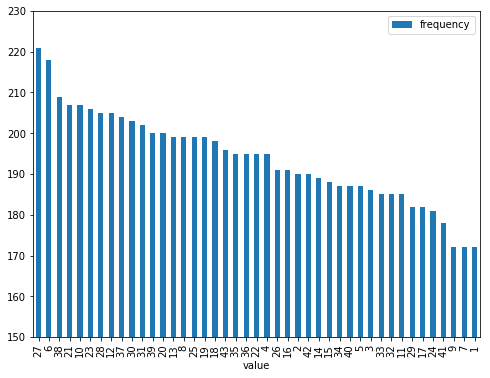
グラフを見たところ、よく出ている数字(6や27)は、220回程度出ているのに対し、あまり出ていない数字(1や7や9)は170回程度であり、そこそこ偏りが発生しているように見えますね。
偏りの評価
次に、1~43までの数値のことは一旦忘れ、この偏り自体を確認・評価していきます。こういう場合、横軸をfrequencyとしてヒストグラムをプロットしてみると分かりやすいです。
#ヒストグラムをプロット
df.plot.hist(bins=7)

どうやら、190~200回を分布のピークとした形状のようです。おおよそ正規分布的と仮定して、分布の平均と標準偏差を計算してみましょう。
#平均と標準偏差を計算
print("平均:" + "{0:.3f}".format(df.mean().values[0]))
print("標準偏差:" + "{0:.3f}".format(df.std().values[0]))
上記の数字がこの分布の偏りの指標となります。
偏りの時系列的変化
次に、この偏りの指標(平均及び標準偏差)がloto6の歴史の中でどう評価してきたかを算出してみましょう。
まず、loto6のデータフレームを受け取り、平均と標準偏差を返すファンクションを作成します。
#loto6のデータフレームを受け取り、平均と標準偏差を返すファンクション
#dfがデータフレーム、iは開催回数を表す。
def getdistInfo(df, i):
#指定した開催日までのデータを抽出
df = df.ix[:i]
#andasのmeltを用いて数値を1列の項目に変換
df = pd.melt(df)
#pivot-tableを用いて数値ごとの抽選回数を算出
df = pd.pivot_table(df, index='value', aggfunc='count')
df.columns = ['frequency']
#分布の平均と標準偏差を返す
return df.mean().values[0], df.std().values[0]
このファンクションに渡すiを増やしながらreturnを受け取ることで、偏りの時系列変化を算出することができます。
#データフレームを読み直す
tdf = pd.read_csv("loto6.csv", encoding="cp932", parse_dates=[1])
df = tdf.iloc[:, 3:10]
result = []
for i in df.index:
result.append(getdistInfo(df, i))
result = pd.DataFrame(result, columns=['mean', 'std'], index=tdf['抽せん回'])
result.index.name = 'times'
可視化してみましょう。
result.plot(subplots=True, figsize=(6, 8))
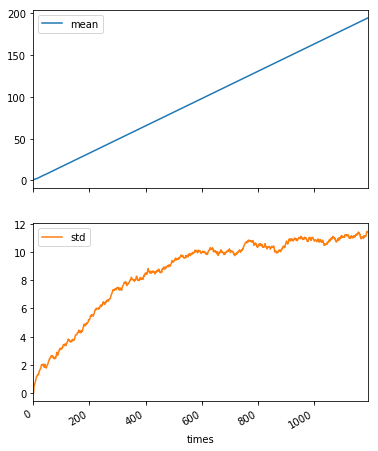
抽選回数で規格化するとこんな感じ。
(result.T / result.index.values).T.plot(subplots=True, figsize=(6, 8))
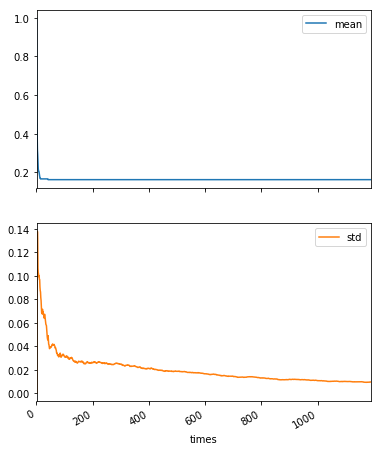
平均についてはほとんど変化がなく、標準偏差はゆっくりと減っていくという結果のようです。
偏りは統計的に妥当か?
次に、この偏りが統計的に妥当かを評価していきます。loto6が本当に完全なランダムであれば、1~43のうち7つの数字を無作為に抽出するシミュレーションを、開催回数分行って計算した偏りの指標(平均値及び標準偏差)が、上記で算出した値とほぼ一致するはずですので、それを検証します。
なお、このような確率モデルを使った無作為なシミュレーションにより何らかの指標を評価することを「モンテカルロシミュレーション」と呼びます。
モンテカルロシミュレーションの方法
本ケースにおいては1~43までの配列から7つの数字を無作為に選択することに相当します。
#numpyを使ってモンテカルロシミュレーション
import numpy as np
#プログラムに再現性を持たせるため乱数のシードを設定
np.random.seed(0)
#1~43の数字から重複なしで7つの数字を選択
data = np.random.choice(range(1, 44), replace=False, size=7)
data.sort()
#結果確認
print(data)
モンテカルロシミュレーション結果との比較
これを所定の回数繰り返して仮想的なloto6の結果を作りましょう。
datas = []
numbers = list(range(1, 44))
np.random.seed(0)
for i in df.index:
data = np.random.choice(numbers, replace=False, size=7)
data.sort()
datas.append(data)
vloto6 = pd.DataFrame(datas, index=df.index, columns=df.columns)
#結果確認
vloto6.head()
得られた結果を先ほど作ったgetdistInfoを用いて可視化してみます。
vresult = []
for i in df.index:
vresult.append(getdistInfo(vloto6, i))
vresult = pd.DataFrame(vresult, columns=['mean', 'std'], index=tdf['抽せん回'])
vresult.index.name = 'times'
抽選回数で規格化した結果で見てみましょう。
(vresult.T / vresult.index.values).T.plot(subplots=True, figsize=(6, 8))
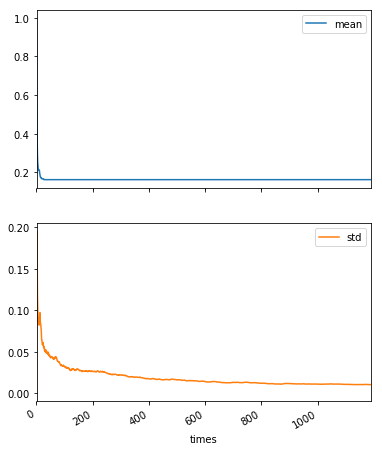
meanがほぼ同じことは分かりますが、これだけだとstdは良く分からないので、stdに絞って重ねて書いてみます。
#シミュレーションを青、実際を赤で描画
ax = (vresult.T / vresult.index.values).T['std'].plot(c='b')
(result.T / result.index.values).T['std'].plot(c='r', ax=ax)
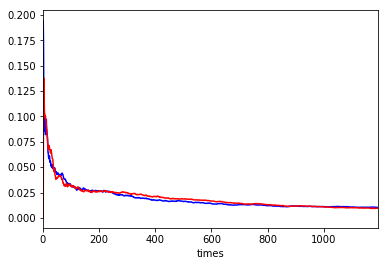
実績(赤)とシミュレーション(青)の結果はほぼ等しく、やはりloto6はランダムと言えそうです。
100回のモンテカルロシミュレーション結果との比較
せっかくなのでモンテカルロシミュレーションを繰り返して、より妥当性を確認してみましょう。まずモンテカルロシミュレーションから統計値を出す部分をファンクション化します。
#loto6のデータフレームを受け取り、標準偏差の時系列変化を返すファンクション
#dfがloto6の実際の結果の抽出番号のデータフレーム、tdfはそれ以外も含めたもの。jは乱数のシードを表す。
def loto6simulation(df, tdf, j):
#仮想的なloto6の結果を作成
datas = []
numbers = list(range(1, 44))
np.random.seed(j)
for i in df.index:
data = np.random.choice(numbers, replace=False, size=7)
data.sort()
datas.append(data)
vloto6 = pd.DataFrame(datas, index=df.index, columns=df.columns)
#時系列的な標準偏差の変化を算出
vresult = []
for i in df.index:
vresult.append(getdistInfo(vloto6, i))
vresult = pd.DataFrame(vresult, columns=['mean', 'std'], index=tdf['抽せん回'])
vresult.index.name = 'times'
return (vresult.T / vresult.index.values).T['std']
jを1万回繰り返せばその分の結果が返ってきます。ただし、繰り返し回数が多いので、並列計算を使ってみましょう。
#ライブラリのインポート
from joblib import Parallel, delayed
#これがないとjoblibが止まるので入れておく
if __name__ == "__main__":
#n_jobsがコア数
vresults = Parallel(n_jobs=1, verbose=1)([delayed(loto6simulation)(df, tdf, j) for j in range(100)])
#concatを使って結合
vresults = pd.concat(vresults, axis=1)
#結果確認
vresults.head()
先ほどと同様の手順で可視化してみましょう。
ax = vresults.plot(legend=False, c='b', figsize=(9, 6))
(result.T / result.index.values).T['std'].plot(c='r', ax=ax)
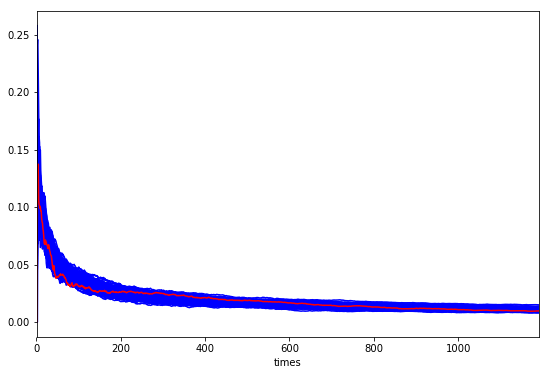
赤い線(実際)は青い線(シミュレーション)のなかにすっぽり埋まっていますね。やはり完全にランダムと言ってよさそうです。
まとめ
データの確認とモンテカルロシミュレーションを用いた検証により以下のことが分かりました。ロト6は、偏りがありそうではありますが、基本ランダムと言えそうです。
- 今までに出た目は偏りがあるか?
⇒よく出ている数字(6や27)は、220回程度出ているのに対し、あまり出ていない数字(1や7や9)は170回程度であり、偏りがありそうに見える - 偏りは統計的に妥当か?
⇒分布のばらつきはランダムを仮定した場合のシミュレーション結果とほぼ一致しており、統計的に妥当な偏り=ランダムで予測不可
その3では、当たった数字と賞金の関係を分析し、いつどんな数字を選択すると期待値が上がるのか、ということを分析しようと思います。
memo jpyterをwordpress用のhtmlに変換 jupyter nbconvert –to html –template basic xxx.ipynb
私も同じことをしたいのですが、何の本を読めばいいのでしょうか?
本格的に学ばれるなら、モンテカルロ法(又はモンテカルロ・シミュレーション)に関する書籍をお読みになられると良いと思います。まずは試してみたいという感じでしたら、「モンテカルロ法 python」くらいでwebを調べれば良いサイトが見つかるかと思います!