概要
以下に示す5行4列のデータをサンプルに、Pandasのデータ選択手法を整理しました。
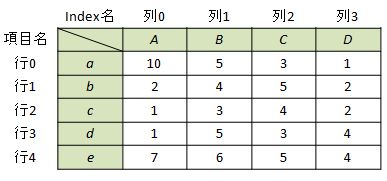
ひとまずデータを作成し読み込んでおきます。
#必要なモジュールのインポート
import pandas as pd
if __name__ == "__main__":
#サンプルデータ作成
df = pd.DataFrame(index=["a", "b", "c", "d", "e"],
columns=["A", "B", "C", "D"],
data=[[10, 5, 3, 1],[2, 4, 5, 2],
[1, 3, 4, 2],[1, 5, 3, 4],
[7, 6, 5, 4]]
)
列の選択方法
ケース1-1:1列を選択する場合
例として”項目A”を選択する場合を考えます。この場合、①項目名を指定する、②列番号を指定する、の2つの方法があります。
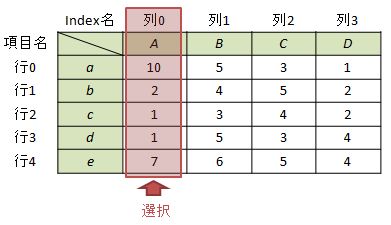
#①項目名を指定する場合 df["A"] #又は df[["A"]]
#②列番号を指定する場合 df[[0]]
列番号を指定する場合は入れ子で与える必要があることに注意してください。いずれの方法でも”項目A”が抽出できますが、体感的には「①項目名を指定する」の方がコーディングのミスが出にくいと感じています。また、細かい話ですが、①の上の方式はreturnがSeries型で、下の方式はDataFrame型で返ってきます。覚えておくと役立つかもしれません。
Out[1]:
A
a 10
b 2
c 1
d 1
e 7
ケース1-2:複数列を選択する場合
例として”項目A”と”項目B”を指定する場合を考えます。1列を選択した場合と同様に、名称によるアクセスと列番号によるアクセスの2つの方法があります。
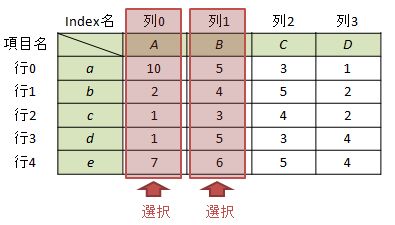
#①項目名を指定する場合 df[["A", "B"]] #又は df[["A"]+["B"]]
#②列番号を指定する場合 df[[0, 1]] #又は df[[0]+[1]]
この場合、どちらの方法でも入れ子で与える必要があります。もちろんいずれの方法でも”項目A”と”項目B”を抽出できます。
Out[2]:
A B
a 10 5
b 2 4
c 1 3
d 1 5
e 7 6
ケース1-3:複数列を選択する場合(その2)
ケース1-2の方法だと、選択する列数が増えてきた時にいちいちコーディングするのが面倒ですね。そこでスライシングを使って複数の列を選択する方法が有効になります。先程と同様に”項目A”と”項目B”を選択してみます。
.jpg)
#①項目名を指定する場合 df.ix[:, "A":"B"]
#②列番号を指定する場合 df.ix[:, 0:2] #又は df[df.columns[0:2]]
ixはテーブル全体へのアクセスを表し[行、列]を引きます。行はすべて使うので:とし、列をスライシングで指定しています。また、df.columnsがカラム名のリストになることを使って、カラム名をスライシングして指定することも可能です。この場合はixは不要です。
得られる結果は同様です。
Out[3]:
A B
a 10 5
b 2 4
c 1 3
d 1 5
e 7 6
ケース1-4:複数列を選択する場合(その3)
さらに、1つのスライシングで指定できない「飛んだ複数の列」を選択する場合です。例として”項目A”と”項目B”と”項目D”を選択してみます。
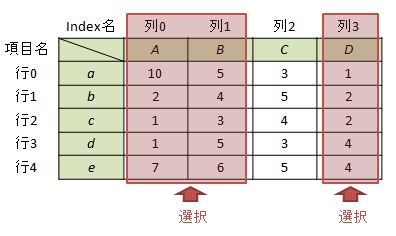
#②列番号を指定する場合 df[df.columns[0:2] + df.columns[3:4]] 又は df[df.columns[0:2] | df.columns[3:4]]
この場合、ix方式では(おそらく)実現できないため、df.columnsを使って選択すると良いと思われます 。
Out[4]:
A B D
a 10 5 1
b 2 4 2
c 1 3 2
d 1 5 4
e 7 6 4
行の選択方法
ケース2-1:1行を選択する場合
例として”Index a”を選択する場合を考えます。この場合、①Index名を指定する、②行番号を指定する、の2つの方法があります。
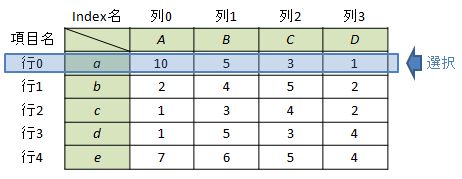
#①Index名を指定する場合 df.ix["a"] #又は df.ix[["a"]]
#②行番号を指定する場合 df.ix[0] #又は df.ix[[0]]
行を選択する場合はixを使います。いずれの方法でも”Index a”が抽出できます。その他の内容は列の場合と同様なので省略します。
Out[1]:
A B C D
a 10 5 3 1
ケース2-2:複数行を選択する場合
例として”Index a”と”Index b”を指定する場合を考えます。
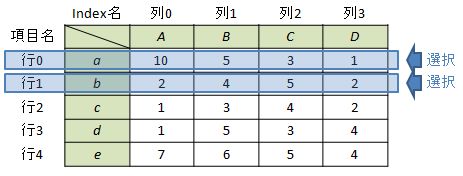
#①Index名を指定する場合 df.ix[["a", "b"]] #又は df.ix[["a"]+["b"]]
#②行番号を指定する場合 df.ix[[0, 1]] #又は df.ix[[0]+[1]]
列選択との違いはixを付けることだけです。
Out[2]:
A B C D
a 10 5 3 1
b 2 4 5 2
ケース2-3:複数行を選択する場合(その2)
スライシングを使って”Index a”と”Index b”を一括選択してみます。
.jpg)
#①Index名を指定する場合 df["a":"b"] #又は df.ix["a":"b"]
#②行番号を指定する場合 df[0:2] #又は df.ix[0:2] #又は df.ix[df.index[0:2]]
列でixが必要になったのに対し、行はixを使っても使わなくても指定できます。ちょっとややこしいので、「行を指定する場合は常にixを付ける」と考えた方が混乱がないかもしれません。
得られる結果は同様です。
Out[3]:
A B C D
a 10 5 3 1
b 2 4 5 2
ケース2-4:複数行を選択する場合(その3)
1つのスライシングで指定できない「飛んだ複数の行」を選択する場合です。例として”Index a”と”Index b”、”Index d”と”Index e”を選択してみます。
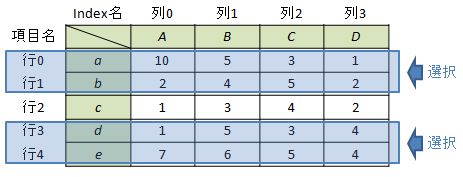
#②行番号を指定する場合 df.ix[df.index[0:2] + (df.index[3:5])] 又は df.ix[df.index[0:2] | (df.index[3:5])]
列の場合と同様に、df.indexを使って選択すると良いと思われます 。
Out[4]:
A B C D
a 10 5 3 1
b 2 4 5 2
d 1 5 3 4
e 7 6 5 4
要素の選択方法
ケース3-1:1要素を選択する場合
例として”項目AのIndex a”を選択する場合を考えます。この場合、①Index名を指定する、②行番号を指定する、の2つの方法があります。ixで[行, 列]の順に選択すればよいだけなのですが、1要素の場合は指定方法によって戻り方が結構異なるので注意が必要です。
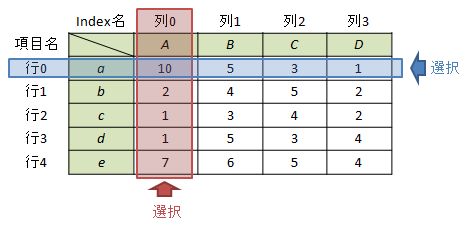
スカラーで戻るパターン
df.ix["a", "A"] #又は df.ix[0, 0] Out[1]: 10
Name a のSeriseで戻るパターン
df.ix["a", ["A"]] #又は df.ix[0, [0]] Out[1]: A 10 Name: a, dtype: int64
Name A のSeriseで戻るパターン
df.ix[["a"], "A"] #又は df.ix[[0], 0] Out[1]: a 10 Name: A, dtype: int64
DataFrameで戻るパターン
df.ix[["a"], ["A"]]
#又は
df.ix[[0], [0]]
Out[1]:
A
a 10
ケース3-2:複数要素を選択する場合
ixで[行, 列]の順に選択すればよく、ここまで書いた列選択・行選択を組み合わせるだけですので割愛します。
条件に一致する部分(列・行・要素)の選択方法
ケース4-1:1つの条件を指定
例として”項目Aの値が2以下のindexのみ”を選択する場合を考えます。
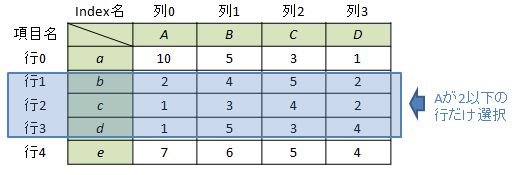
やり方はixの中身に条件式を入力するだけです。なお、df[“A”]のように戻り値がSeries型になっている必要があることに注意して下さい。(df[[“A”]]のようなDataFrame型ではエラー。)
df.ix[df["A"]<=2] #又は df.ix[df[df.columns[0]]<=2] Out[1]: A B C D b 2 4 5 2 c 1 3 4 2 d 1 5 3 4
ちなみに、内部的には以下のBool配列を受け取ったことと同義です。
df.ix[[False, True, True, True, False]] Out[2]: A B C D b 2 4 5 2 c 1 3 4 2 d 1 5 3 4
ケース4-2:2つ以上の条件を指定
例として”項目Aの値が2以下かつ、項目Bの値が4以上のindexのみ”を選択する場合を考えます。
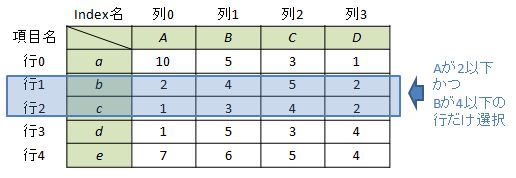
複数条件を指定するためには、条件式を()で囲い、&(or条件の場合は|)を使って記載すればand条件として処理されます。
df.ix[(df["A"]<=2) & (df["B"]<=4)] #又は df.ix[(df[df.columns[0]]<=2) & (df[df.columns[1]]<=4)] Out[4]: A B C D b 2 4 5 2 c 1 3 4 2
ケース4-3:2つ以上の条件を指定(その2)
より複雑な条件として、”項目にA又はC又はDを含み、かつ項目Dが2以上”という条件を考えます。
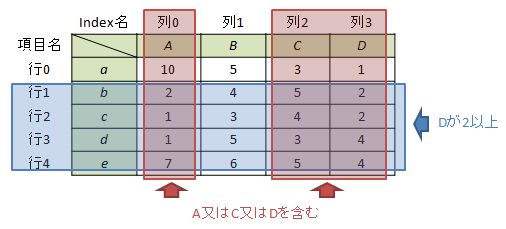
含み、という条件を表現するためにはisinを使うのが有効です。
df.ix[df["D"]>=2, df.columns.isin(["A", "C", "D"])] Out[5]: A C D b 2 5 2 c 1 4 2 d 1 3 4 e 7 5 4
ケース4-4:2つ以上の条件を指定(その3)
さらに複雑な条件として、”項目にA又はC又はDを含み、かつ項目Dが2以上、Index dが3以上4以下”という条件を考えます。
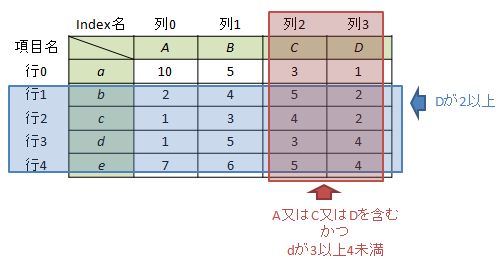
大分ややこしくなって来ましたが、ルールは同様であり、1行で書くことができます。
df.ix[df["D"]>=2, (df.columns.isin(["A", "C", "D"])) & (df.ix["d"]>=3) & (df.ix["d"]<=4)] Out[6]: A B C D b 2 4 5 2 c 1 3 4 2
行番号とIndex名、列番号と項目名に重複がある場合について
上記までの取り組みは、暗黙の了解として「行番号とIndex名、列番号と項目名は一致しない」という前提で進めていました。仮に以下のようなデータの場合、ixで重複した値を指定するとどうなるのでしょうか。
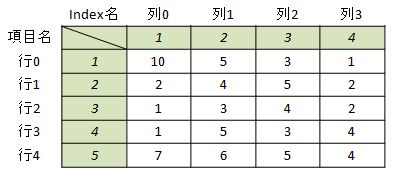
ひとまずデータを作成し読み込んでおきます。
#必要なモジュールのインポート
import pandas as pd
if __name__ == "__main__":
#サンプルデータ作成
df2 = pd.DataFrame(index=[1, 2, 3, 4, 5],
columns=[1, 2, 3, 4],
data=[[10, 5, 3, 1],[2, 4, 5, 2],
[1, 3, 4, 2],[1, 5, 3, 4],
[7, 6, 5, 4]]
)
ケース5-1:通常通り選択した場合
1の列を選択すると、行番号ではなく項目名が1のものが優先される。
df2[[1]]
Out[2]:
1
1 10
2 2
3 1
4 1
5 7
1の行を選択すると、列番号ではなくIndex名が1のものが優先される。
df2.ix[[1]]
Out[2]:
1 2 3 4
1 10 5 3 1
上述の通り重複したものがあった場合は自動的に項目名・Index名が優先されるようです。
ケース5-2:ilocで選択した場合
もしも行番号・列番号を優先したい場合にはilocを使いましょう。ilocを指定した場合、項目名・Index名は検索対象から除外されます。
ilocで1の列を選択すると、行番号が1のものが優先される。
df2.iloc[:, [1]] Out[3]: 2 1 5 2 4 3 3 4 5 5 6
ilocで1の行を選択すると、列番号が1のものが優先される。
df2.iloc[[1]] Out[4]: 1 2 3 4 2 2 4 5 2
ケース5-3:locで選択した場合
また反対に、行番号・列番号を検索対象から除外したい場合にはlocを使います。
locで1の列を選択すると、ixと同様にIndex名が1のものが優先される。
df2.loc[:, [1]]
Out[3]:
1
1 10
2 2
3 1
4 1
5 7
locで1の行を選択すると、ixと同様に項目名が1のものが優先される。
df2.loc[[1]]
Out[4]:
1 2 3 4
1 10 5 3 1
まとめ
Pandasを使ったデータ選択についてまとめました。基本的には以下を押させておけばいいと思います。
- 列を選択する時はdf[“hoge”]を使う
- 行・又は要素を選択する時はdf.ix[“hoge”, “hoge”]を使う
- 特定要素を選択する場合には[“hoge”]内に条件式を組み込む
- 項目名やIndex名が番号と重複している場合、iloc(番号優先)又はloc(名称優先)を使い分ける