概要
Pythonでデータを分析しようとした時、Header行が複数行あると1回のread_csvではヘッダー情報とデータ値の両方をうまく読み込むことができません。対策としては以下が考えられますが、1はデータアナリストとして不本意。そこで本記事では2の内容について説明していきます。
- Excelで元ファイルをHeader1行になるように変更する
- ヘッダー情報とデータ値を分けて読み込む
サンプルデータ
サンプルデータとして以下を使います。上2行にヘッダー情報、4行目以下からデータ値が入っています。
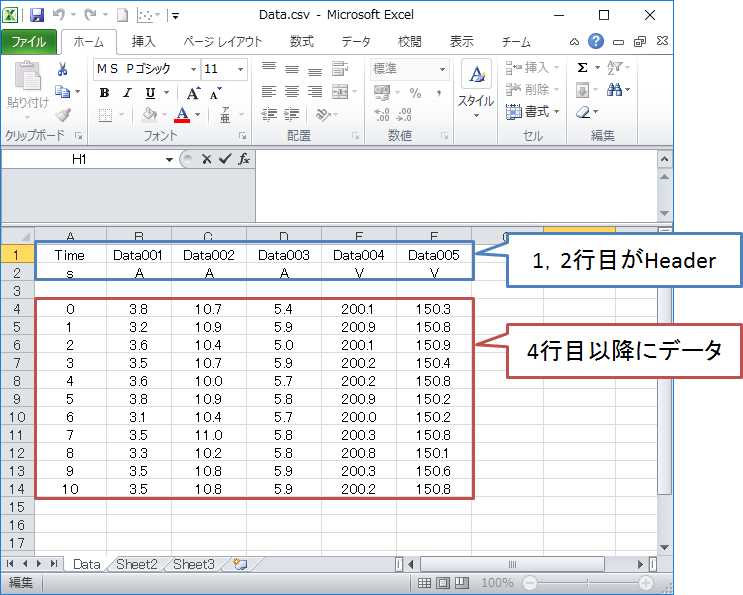
サンプルデータ
読み込み方法
ヘッダー情報の読み込み
まずはpandasのread_csvのheader及びnrowsオプションを使って上2行のデータだけを読み込み、その後その情報を結合することでヘッダー情報にします。ここでは2行目が単位なので[]で囲む処理をしています。
#pandasのインポート
import pandas as pd
#2行だけデータ読み込み
temp = pd.read_csv("Data.csv",
header=None,
nrows=2)
#Header作成
header = temp.ix[0] + "[" + temp.ix[1] + "]"
#作成結果確認
print(header)
実行結果
ヘッダーデータが得られました。
0 Time[s] 1 Data001[A] 2 Data002[A] 3 Data003[A] 4 Data004[V] 5 Data005[V] dtype: object
データ値の読み込み
次にpandasのread_csvのheader及びskiprowsオプションを使って4行以降のデータだけを読み込みます。
#4行目以降のデータだけ読み込み
df = pd.read_csv("Data.csv",
header=None,
skiprows=3)
#結果確認
print(df)
実行結果
データ値のみが入ったデータフレームが得られました。
0 1 2 3 4 5
0 0 3.8 10.7 5.4 200.1 150.3
1 1 3.2 10.9 5.9 200.9 150.8
2 2 3.6 10.4 5.0 200.1 150.9
3 3 3.5 10.7 5.9 200.2 150.4
4 4 3.6 10.0 5.7 200.2 150.8
5 5 3.8 10.9 5.8 200.9 150.2
6 6 3.1 10.4 5.7 200.0 150.2
7 7 3.5 11.0 5.8 200.3 150.8
8 8 3.3 10.2 5.8 200.8 150.1
9 9 3.5 10.8 5.9 200.3 150.6
10 10 3.5 10.8 5.9 200.2 150.8
ヘッダー情報とデータ値の結合
上記で読み込んだデータフレームのカラム名にヘッダー情報を指定し、データを完成させます。
#カラム名にheaderを指定 df.columns = header #結果確認 print(df)
実行結果
複数行のHeader情報を正しく認識したデータフレームが得られました。
Time[s] Data001[A] Data002[A] Data003[A] Data004[V] Data005[V]
0 0 3.8 10.7 5.4 200.1 150.3
1 1 3.2 10.9 5.9 200.9 150.8
2 2 3.6 10.4 5.0 200.1 150.9
3 3 3.5 10.7 5.9 200.2 150.4
4 4 3.6 10.0 5.7 200.2 150.8
5 5 3.8 10.9 5.8 200.9 150.2
6 6 3.1 10.4 5.7 200.0 150.2
7 7 3.5 11.0 5.8 200.3 150.8
8 8 3.3 10.2 5.8 200.8 150.1
9 9 3.5 10.8 5.9 200.3 150.6
10 10 3.5 10.8 5.9 200.2 150.8
参考:全ソースコード
#pandasのインポート
import pandas as pd
#2行だけデータ読み込み
temp = pd.read_csv("Data.csv",
header=None,
nrows=2)
#Header作成
header = temp.ix[0] + "[" + temp.ix[1] + "]"
#作成結果確認
print(header)
#4行目以降のデータだけ読み込み
df = pd.read_csv("Data.csv",
header=None,
skiprows=3)
#結果確認
print(df)
#カラム名にheaderを指定
df.columns = header
#結果確認
print(df)
まとめ
Headerが複数行あるようなデータでも上のような方法で簡単に読み込めますので、ファイル数が多い場合などはExcelで処理する前に是非試してみてください!