概要
Pythonにはscikit-learnという便利な機械学習モジュールがありますが、この中のtreeを使って学習した決定木構造がどこに格納されているのかが分かりにくかったので整理しました。
以降では、scikit-learnが持っているサンプルデータ(iris)を使って決定木学習をしたデータを対象に確認していきます。
#必要なモジュールのインポート
from sklearn.datasets import load_iris
from sklearn import tree
if __name__ == "__main__":
#irisデータの読み込み
iris = load_iris()
#決定木学習
clf = tree.DecisionTreeClassifier()
clf.fit(iris.data, iris.target)
過去記事を参考に決定木を画像化するとこんな感じ。
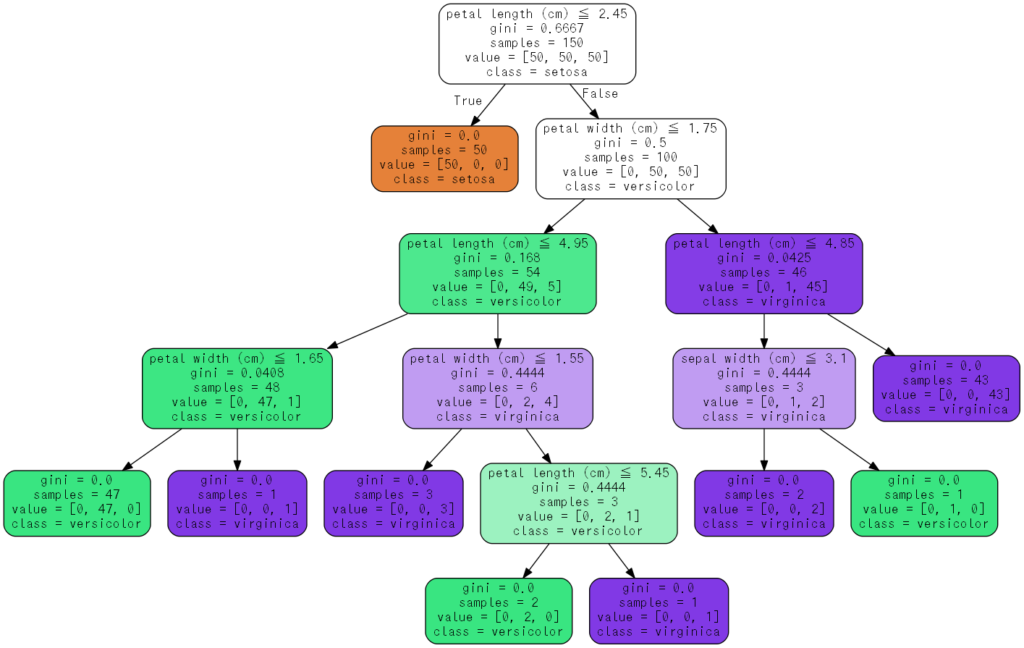
構造情報取得方法
情報の格納先
学習した決定木構造は基本的にオブジェクトの.tree_メンバが保有しています。以下、取得したい情報別に、.tree_のどのメンバにアクセスすればいいかを列挙していきます。
各ノードの分岐条件の変数名
clf.tree_.featureと入力することで、各ノードの分岐条件の変数IDが取得できます。
以下が出力結果。IDと名称の関係はiris.feature_namesが持っています。-2は分岐条件がないこと(リーフであること)を示します。
array([ 0, -2, 1, 0, 1, -2, -2, 1, -2, 0, -2, -2, 0, -2, -2], dtype=int64)
各ノードの分岐条件の閾値
clf.tree_.thresholdと入力することで、各ノードの分岐条件の閾値が取得できます。
以下が出力結果。scikit-learnのモジュールでは分岐の不等号の方向は常に≦で扱われるので省略されています。
array([ 2.45000005, -2. , 1.75 , 4.94999981, 1.6500001 ,
-2. , -2. , 1.54999995, -2. , 5.44999981,
-2. , -2. , 4.85000038, -2. , -2. ])
各ノードの到達データの偏り度
clf.tree_.impurityと入力することで、各ノードの分岐条件の偏り度が取得できます。
以下が出力結果。指標は学習時に指定された指標(giniやinfoGain等)となるため省略されています。
array([ 0.66666667, 0. , 0.5 , 0.16803841, 0.04079861,
0. , 0. , 0.44444444, 0. , 0.44444444,
0. , 0. , 0.04253308, 0.44444444, 0. ])
各ノードの到達データ総数
clf.tree_.n_node_samplesと入力することで、各ノードの到達データ総数が取得できます。
以下が出力結果。
array([150, 50, 100, 54, 48, 47, 1, 6, 3, 3, 2, 1, 46,
3, 43], dtype=int64)
各ノードのクラス別到達データ数
clf.tree_.valueと入力することで、各ノードのクラス別到達データ数が取得できます。
以下が出力結果。順番とクラスの関係はiris.target_namesが持っています。
array([[[ 50., 50., 50.]],
[[ 50., 0., 0.]],
[[ 0., 50., 50.]],
[[ 0., 49., 5.]],
[[ 0., 47., 1.]],
[[ 0., 47., 0.]],
[[ 0., 0., 1.]],
[[ 0., 2., 4.]],
[[ 0., 0., 3.]],
[[ 0., 2., 1.]],
[[ 0., 2., 0.]],
[[ 0., 0., 1.]],
[[ 0., 1., 45.]],
[[ 0., 1., 2.]],
[[ 0., 0., 43.]]])
各ノードの最多数クラス
残念ながら関数を持っていなさそうですが、clf.tree_.valueとnumpyのargmaxを使って計算できます。
#私の環境では一旦転置しないとうまく動きませんでした。 np.argmax(clf.tree_.value.T, axis=0)
以下が出力結果。順番とクラスの関係は上と同様にiris.target_namesが持っています。
array([[0, 0, 1, 1, 1, 1, 2, 2, 2, 1, 1, 2, 2, 2, 2]], dtype=int64)
木構造(各ノードの親子関係)
clf.tree_.children_leftで左側の子ノードIDを、clf.tree_.children_rightで右側の子ノードIDを取得できます。
clf.tree_.children_left clf.tree_.children_right
以下が出力結果。値が子ノードIDを示しており、リーフ(子ノードがない)は-1で表記されています。ID番号の付け方はPreorder traversal sequence(深さ方向探索)となっているようです。
#children_left array([ 1, -1, 3, 4, 5, -1, -1, 8, -1, 10, -1, -1, 13, -1, -1], dtype=int64) #children_right array([ 2, -1, 12, 7, 6, -1, -1, 9, -1, 11, -1, -1, 14, -1, -1], dtype=int64)
まとめ
決定木の可視化をgraphviz以外で実施したいなと考えたため、まずはscikit-learnで学習した決定木構造の抽出方法について整理しました。皆様のお役にも立てば幸いです。