概要
オセロのAIを考えていく上で、AlphaGoは必ず押させておきたい内容だったので、文献等を調査して内容をメモのレベルではありますが整理しました。本記事では、AlphaGo Zeroまでは含んでおらず、それよりも古い段階のAlphaGo(参考文献1)について記載しています。整理した内容は以下です。
- 機械学習・強化学習で何を学習するのか
- 手の探索方法
参考文献
1が元文献、2及び3は文献を元に内容を解説した図書、4はオセロへの適用を検討した資料です。
機械学習・強化学習で何を学習するのか
AlphaGoではニューラルネットワークを使って以下の4ネットワークを学習しています。
- ロールアウト用のポリシーネットワーク
- 手の探索や強化学習の事前確率として使うポリシーネットワーク(SL)
- バリューネットワークの訓練用データを生成するポリシーネットワーク(RL)
- 手の探索の精度を上げるためのバリューネットワーク(VL)
ポリシーネットワークとは、局面を入力にして、打ち手の確率を返すネットワークです。また、バリューネットワークとは局面を入力にして、勝率を返すネットワークです。
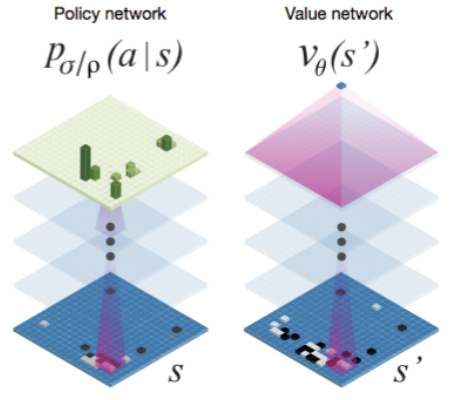
ロールアウト用のポリシーネットワークは、単純な構成であるロジスティクス回帰を使っていて、プロの棋譜を教師として学習します。打ち手の選択精度は30%以下と低いですが、他のネットワークに比べて動作が早いです。また従来の囲碁ソフトで使っていたような人的な細かい特徴量を入力にしています。なお、ロールアウトとは、ある局面から乱数的に手を選んで終局まで進め、勝敗をシミュレーションすることを指しています。
手の探索や強化学習の事前確率として使うポリシーネットワークは、CNNを使っていて、同様にプロの棋譜を教師として学習します。打ち手の選択精度は55%程度と高いですが、ロールアウトに比べると2000倍程度動作が遅いです。なので、精度を要する部分にのみ限定して使います。なお、局面をほぼそのままCNNに入れるので、特徴的な要素はかなり減らしており、所謂DNNの特徴量学習能力を活用しています。
バリューネットワークの訓練用データを生成するポリシーネットワークは、上記ポリシーネットワーク(SL)で自分同士で対戦して棋譜を作り、勝ち負けの結果から強化学習を実施したものです。SLに対しては80%程度の高い勝率が得られます。
手の探索の精度を上げるためのバリューネットワークは、RLで作った棋譜から、CNNを使って局面と勝敗の関係を学習します。ロールアウトで探索した手ごとの勝率を補正するように使います。
手の探索方法
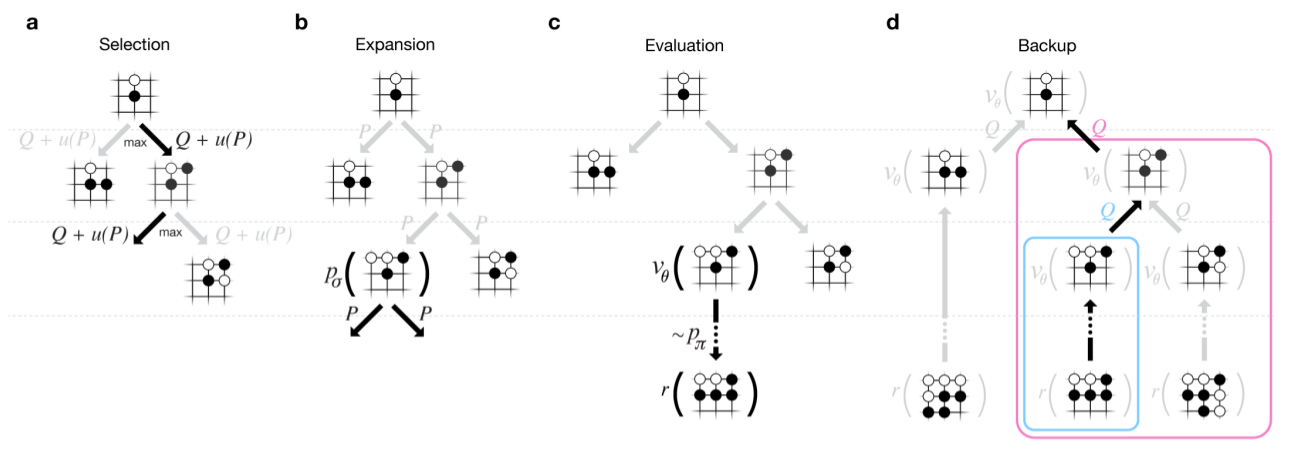
大きくは以下の手順で探索を進めます。
- 今の盤面から、SLの事前確率とロールアウトの結果(ある場合)から、最も有効と考えられる手を選択する(Select)
- その手が選ばれた回数が一定以下の場合、ロールアウト用のポリシーネットワークを使って終局までシミュレーションをする(Evaluation)
- シミュレーション結果から1で選んだ手の勝率を、バリューネットワークの値を加味して更新する(Backup)
- その手が選ばれた回数が一定以上の場合、次の分岐がなければその手の次の手の分岐を追加作成する(Expand)
- その手が選ばれた回数が一定以上の場合、次の分岐があればその分岐に移動して1から繰り返す
- 1-5の繰り返しを時間いっぱいまで進め、最も勝率が高い手を次の手として選択する
この部分がAlphaGoの肝であり、また理解が難しいところです。基本的にはロールアウト用のポリシーネットワークを使ってモンテカルロ探索によるシミュレーションを何回も実施して勝率から手の有効性を評価するのですが、見落としを防ぐため、及び探索範囲を効率化するために、勝率の高い手に絞ってより深堀して検討をすすめるということです。また探索数が少ない時や偏った場合に備えて、単純な勝率だけではなくバリューネットワークで学習した値を加味して評価しています。
まとめ
このAlphaGoが出た時点では、ロールアウトポリシーなど従来の囲碁AIの考えがかなり残っていて、改良段階である形跡が見て取れます。次のAlphaGo Zeroでは教師あり学習はなくなっているなど、よりシンプルになっているので、本ロジックとの違いも含めて見ていきたいと思います。