はじめに
本記事では、loto6の販売実績額のデータをBeautifulSoupを用いたウェブスクレイピングにより取得する手順を整理していきます。
手順は以下になります。
- requestsライブラリを開いてWebサイトから用いてhtmlを取得
- BeautifulSoupライブラリを用いてhtmlから必要な部分を抽出
- Pandasライブラリを用いてデータフレーム化・CSV保存
requestsライブラリを開いてWebサイトから用いてhtmlを取得
まずは必要なライブラリをインポートします。
In [1]:
import requests
次にurlを決めます。今回は、販売実績等のLoto6のデータを提供されているサイト様のURLを指定します。
http://sougaku.com/loto6/data/detail/
In [2]:
url = "http://sougaku.com/loto6/data/detail/"
次にセッションを取得しhtmlを取得します。セッションはとは何か?については以下のサイト様等が参考になると思います。
http://qiita.com/hththt/items/07136ad74127999df271
In [3]:
session = requests.session()
res = session.get(url)
res.encoding = 'utf-8'
#データ確認
print(res.text[:1000])
requestsを使って、htmlレスポンスを取得することができました。
BeautifulSoupライブラリを用いてhtmlから必要な部分を抽出
まずは必要なライブラリをインポートします。
In [4]:
from bs4 import BeautifulSoup
BeautifulSoupに先ほどのhtmlを与えます。
In [5]:
soup = BeautifulSoup(res.text, "html.parser")
#データ確認
print(soup.text[:100])
htmlとして理解しています。
次に実際にhtmlファイルを確認して該当箇所を抽出します。
今回のケースでは「sokuho_tb1」というクラスに入っているので取得します。
In [6]:
soup = soup.find(class_='sokuho_tb1')
#データ確認
print(soup)
販売実績額がありましたね。さらに絞り込んで値を抽出しましょう。
In [7]:
#tdの2番めを取得
soup.find_all('td')[2]
Out[7]:
In [8]:
#さらに必要な部分だけを取り出してintに変換
int(soup.find_all('td')[2].text.replace('\n', '').replace('\t', '')[:-3].replace(',', ''))
Out[8]:
販売実績額が取得できました。
Pandasライブラリを用いてデータフレーム化・CSV保存
まずは必要なライブラリをインポートします。
In [9]:
import pandas as pd
データを格納するためのデータフレームを作成します。
In [10]:
#何回目まで取得するかを指定
last = 1196
#中身が空のデータフレームを定義
result = pd.DataFrame(index=range(1, last+1), columns=['販売実績額'])
#データ確認
result.head()
Out[10]:
for文を使って値を埋めていきます。
In [11]:
#1回毎に販売額を取得して格納
for i in result.index:
#対象回
target = i
#URLを指定
if target == last:
url = "http://sougaku.com/loto6/data/detail/"
else:
url = "http://sougaku.com/loto6/data/detail/index" + str(target) + ".html"
session = requests.session()
res = session.get(url)
soup = BeautifulSoup(res.text, "html.parser")
soup = soup.find(class_='sokuho_tb1')
value = int(soup.find_all('td')[2].text.replace('\n', '').replace('\t', '')[:-3].replace(',', ''))
#print(i, value)
#結果を格納
result.loc[i, '販売実績額'] = value
#結果確認
result.head()
Out[11]:
プロットもしておきましょう。
In [12]:
%matplotlib inline
result.plot()
Out[12]:
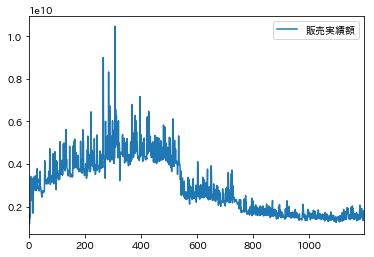
うまく取れてそうですね。最後に保存をして完成です。
In [13]:
result.to_csv("販売実績額.csv")